python抓取京东小米8手机配置信息
本文代码是使用python抓取京东小米8手机的配置信息
首先找到小米8商品的链接:https://item.jd.com/7437788.html
然后找到其配置信息的标签,我们找到其配置信息的标签为 <div class="Ptable">
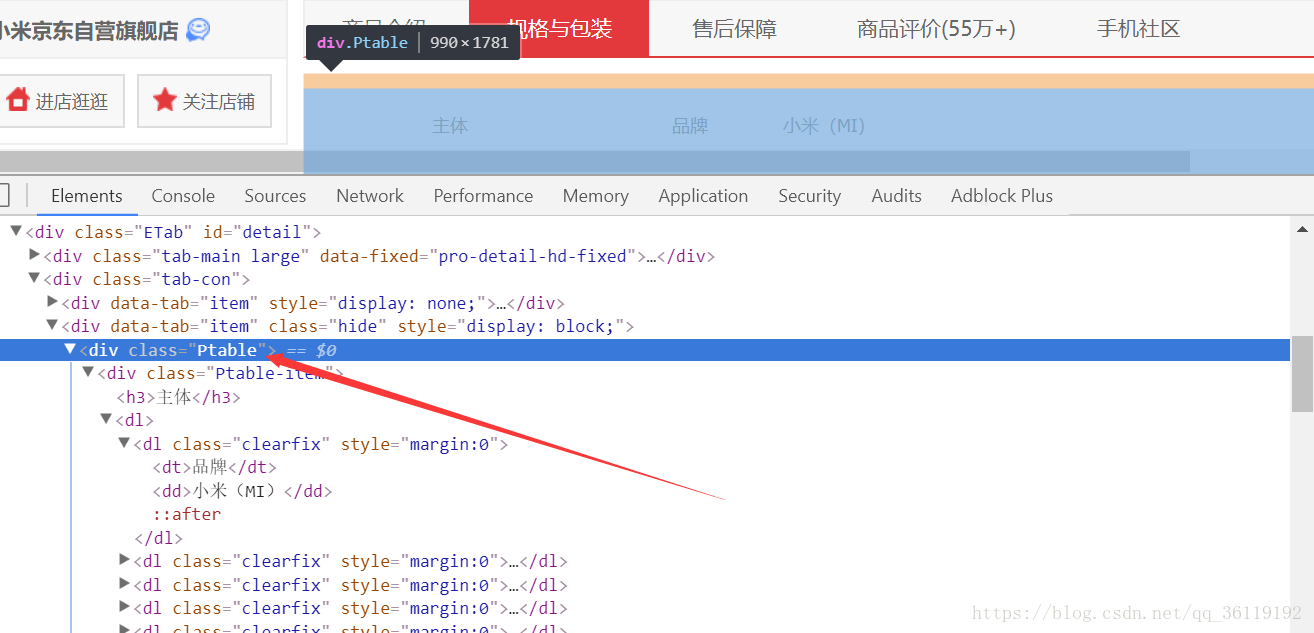
然后再分析其配置信息的页面的规律,我们发现都是dl中包含了dt和dd,而一个dt对应的一个dd,dt对应的是参数,dd对应的是参数具体的值

下面是源代码
import requests
from bs4 import BeautifulSoup
from pandas import Series
from pandas import DataFrame
response=requests.get("https://item.jd.com/7437788.html")
html=response.text
soup=BeautifulSoup(html,"html.parser")
divSoup=soup.find("div",attrs={"class","Ptable"}) ##找到其配置信息的标签
data=DataFrame(columns=["参数","值"]) #定义一个二元的DataFrame
dls=divSoup.find_all("dl")
for dl in dls:
dts=dl.find_all("dt")
dds=dl.find_all("dd")
if len(dts)==len(dds):
for i in range(len(dts)):
f=dts[i].getText();
p=dds[i].getText();
data=data.append(Series([f,p],index=["参数","值"]),ignore_index=True);
print(data)
这是最终抓取到的配置信息,一共有64行,这里我就不一一列举出来了

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。