urllib和BeautifulSoup爬取维基百科的词条简单实例
本文实例主要实现的是使用urllib和BeautifulSoup爬取维基百科的词条,具体如下。
简洁代码:
#引入开发包
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
#请求URL并把结果用UTF-8编码
resp=urlopen("https://zh.wikipedia.org/wiki/Wikipedia:%E9%A6%96%E9%A1%B5").read().decode("utf-8")
#使用BeautifulSoup去解析
soup=BeautifulSoup(resp,"html.parser")
#print(soup)
#获取所有以/wiki/开头的a标签的href属性
listUrl=soup.findAll("a",href=re.compile("^/wiki/"))
#输出所有词条对应的名称和URL
for link in listUrl:
if not re.search("\.(jpg|JPG)$",link["href"]):
print(link.get_text(),"<----->","https://zh.wikipedia.org"+link["href"])
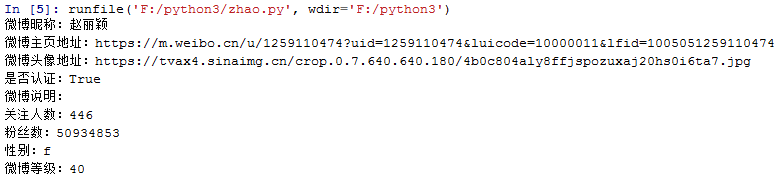
运行结果:

总结
总的来说,Python是简洁而又强大的,调用几个库,就能实现其他语言一大堆代码才能实现的功能。
以上就是本文关于urllib和BeautifulSoup爬取维基百科的词条简单实例的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!