yipeiwu_com6年前
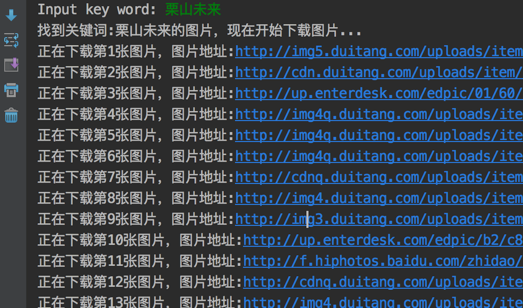
本文实例为大家分享了python抓取网页中链接的静态图片的具体代码,供大家参考,具体内容如下 # -*- coding:utf-8 -*- #http://tieba.baid...
yipeiwu_com6年前
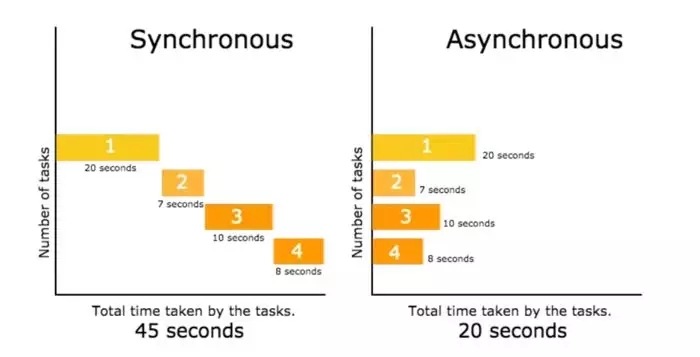
一、同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程...
yipeiwu_com6年前
前言 pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好,和它差不多的还有BeautifulSoup,都是用来解...
yipeiwu_com6年前
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下:...
yipeiwu_com6年前
对于一个net开发这爬虫真真的以前没有写过。这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与Beautifu...
yipeiwu_com6年前
使用Python爬虫登录系统之后,能够实现的操作就多了很多,下面大致介绍下如何使用Python模拟登录。 我们都知道,在前端的加密验证,只要把将加密环境还原出来,便能够很轻易地登录。 首...
yipeiwu_com6年前
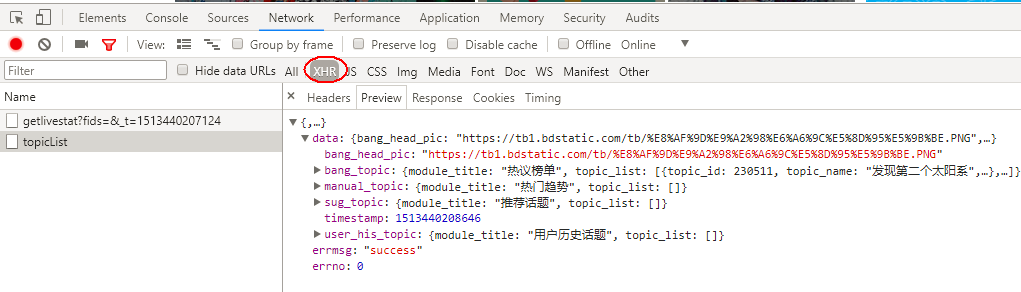
首先确定你要爬取的目标网站的表单提交方式,可以通过开发者工具看到。这里推荐使用chrome。 这里我用163邮箱为例 打开工具后再Network中,在Name选中想要了解的网站,右侧...
yipeiwu_com6年前
# encoding:utf-8 import re # 使用正则 匹配想要的数据 import requests # 使用requests得到网页源码 这个函数是用来得到源码...
yipeiwu_com6年前
一、什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库。它urllib 更加方便,可以节约我们大...
yipeiwu_com6年前
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少。原因他也大概分析了下,就是后面的图片是动态加载的。他的问...