python爬虫获取京东手机图片的图文教程
如题,首先当然是要打开京东的手机页面
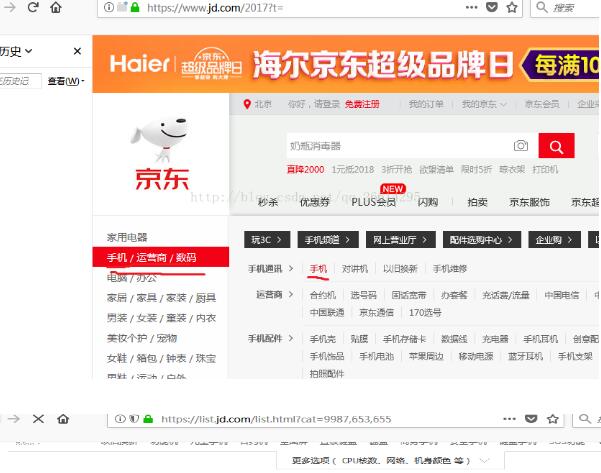
因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面
由观察可以得到,第二页的链接地址很有可能是
https://list.jd.com/list.html?cat=9987,653,655&page=2
那么对应第n页的地址就是
https://list.jd.com/list.html?cat=9987,653,655&page=n
我们就可以利用这个规律在编程的时候打开自己想要获取的页面了
接着我们查看页面的源代码,观察图片链接的规律

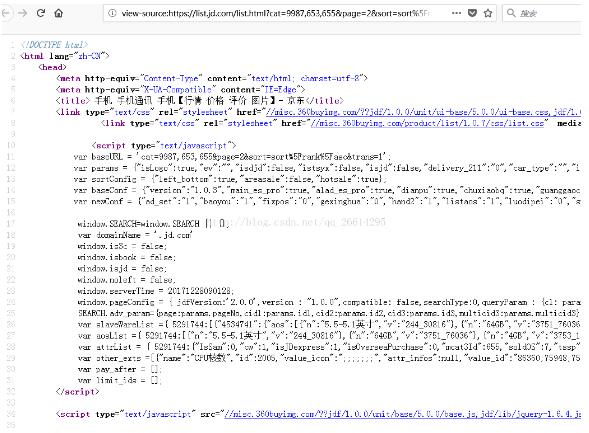
我们使用在源代码的页面使用ctrl+f查找,然后在查找框里面输入页面第一台手机的名字 “vivo X9s 全网通 4GB+64GB 玫瑰金 移动” 快速定位到图片链接附近的代码,便于后面编程对图片范围进行筛选
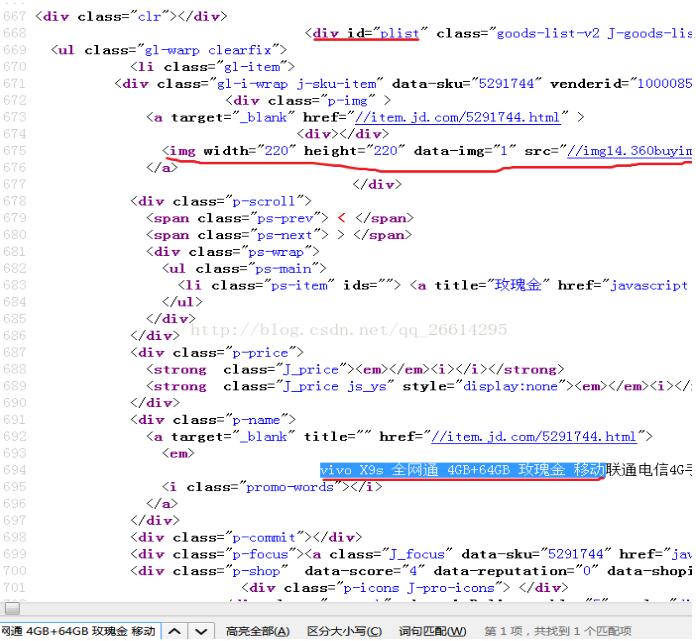
可以看到,上图的画红线的三个部分,<div id="plist" 在这一页中是唯一出现的一个元素,而且离图片链接比较近,所以可以作为筛选页面的开头位置
<img width=“220”……这个是手机图片的信息,我们要获取的是后面
//img14.360buyimg.com/n7/jfs/t6088/107/5539077608/409616/7f98b2bb/596c2edaN9792cd20.jpg
这个链接,但是观察发现后面也有一个图片链接
img data-sku="5291744" width="25" height="25" class="loading-style2" src="//img14.360buyimg.com/n9/jfs/t6088/107/5539077608/409616/7f98b2bb/596c2edaN9792cd20.jpg"
这个很明显不是我们要找的手机图片链接
所以我们要使用正则表达式将真正的图片链接筛选出来,观察发现这两个图片链接的区别在于手机图片链接里面含有n7元素,而另外一个图片链接含有n9元素,这样子我们的正则表达式就可以表示为pat2 = '//.+?/n7/.+?\.jpg'
接着我们要找到这个页面最后一张手机图片的位置,方便找出可以作为筛选页面的结束位置,方法和上面类似,在源代码搜索框输入 小米(MI) 红米Note4X 手机 香槟金 全网通 3GB+32GB 定位到页面最后一张图片位置
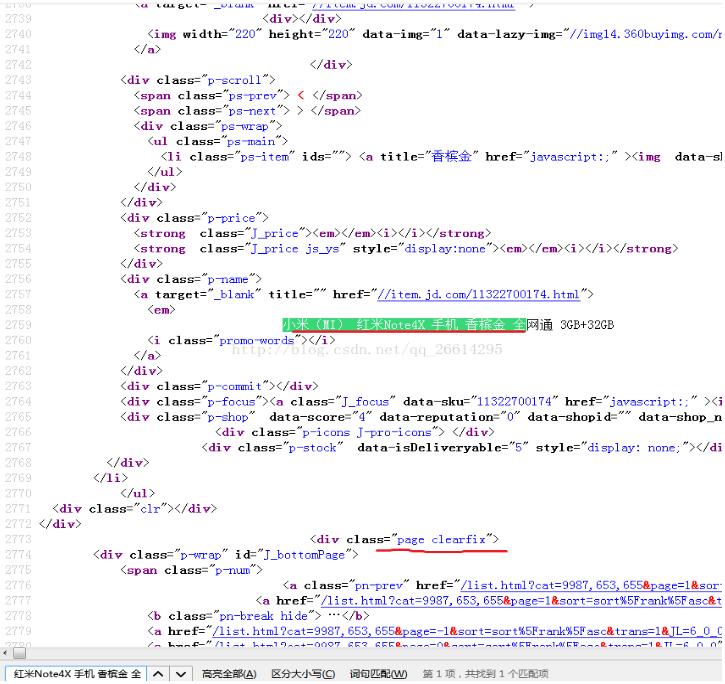
可以看到,下面<div class="page clearfix">在该页面中是唯一的,而且比较接近最后一张手机图片附近的链接,所以可以作为筛选结尾位置的元素,其实筛选的元素只要满足唯一并且接近我们要获取的目标,那么也可以作为我们要选取的元素
经过上面准备之后,我们得出了大概的思路
1首先进行第一次筛选,使用正则表达式pat1 = '<div id="plist".+<div class="page clearfix">'将图片链接的范围大概筛选出来
2然后进行第二次筛选,使用正则表达式pat2 = '//.+?/n7/.+?\.jpg'将手机图片链接筛选出来
3使用urllib.urlretrieve保存链接图片到本地
下面给出python代码
# -*- coding: UTF-8 -*- import re import urllib2 import urllib def craw(url, page): html1 = urllib2.urlopen(url).read() html1 = str(html1) pat1 = '<div id="plist".+<div class="page clearfix">' result1 = re.compile(pat1, re.DOTALL).findall(html1) #获取第一次筛选结果 result1 = result1[0] #*匹配0个或者多个前面表达式 #.匹配任意字符,加上re.dotall包括换行符 #+匹配1个或者多个前面表达式 #?非贪婪匹配,就是只匹配一组 #筛选出图片链接列表 pat2 = '//.+?/n7/.+?\.jpg' imagelist = re.compile(pat2).findall(result1) #x作为图片文件的顺序 x=1 for imageurl in imagelist: imagename = "C:/Users/Administrator/Desktop/jdphone_img/" + str(page) + str(x) + ".jpg" imageurl = "http:" + imageurl try: #保存图片 urllib.urlretrieve(imageurl, filename=imagename) except urllib2.URLError as e: #hasattr判断对象里面是否有name属性 if hasattr(e, "code"): x+=1 if hasattr(e, "reason"): x+=1 x+=1 for i in range(1, 3): url = "https://list.jd.com/list.html?cat=9987,653,655&page=" + str(i) craw(url, i)
注意:我这里只保存了第一二页的手机图片,在进行第二次筛选的时候正则表达式之所以会加了一个"?"进行非贪婪匹配,也就是一次只筛选出一张手机图片链接,如果不加这个非贪婪匹配那么我们会把第一个含有“//”到最后一个结尾含有.jpg之间的所有内容都会筛选出来,显示是不符合的,在这里建议可以把正则表达式的?去掉,然后看一下输出结果,去体会一下非贪婪匹配是怎么样的。