scrapy爬虫实例分享
前一篇文章介绍了很多关于scrapy的进阶知识,不过说归说,只有在实际应用中才能真正用到这些知识。所以这篇文章就来尝试利用scrapy爬取各种网站的数据。
爬取百思不得姐
首先一步一步来,我们先从爬最简单的文本开始。这里爬取的就是百思不得姐的的段子,都是文本。
首先打开段子页面,用F12工具查看元素。然后用下面的命令打开scrapyshell。
scrapy shell http://www.budejie.com/text/
稍加分析即可得到我们要获取的数据,在介绍scrapy的第一篇文章中我就写过一次了。这次就给上次那个爬虫加上一个翻页功能。
要获取的是用户名和对应的段子,所以在items.py中新建一个类。
class BudejieItem(scrapy.Item): username = scrapy.Field() content = scrapy.Field()
爬虫本体就这样写,唯一需要注意的就是段子可能分为好几行,这里我们要统一合并成一个大字符串。选择器的extract()方法默认会返回一个列表,哪怕数据只有一个也是这样。所以如果数据是单个的,使用extract_first()方法。
import scrapy
from scrapy_sample.items import BudejieItem
class BudejieSpider(scrapy.Spider):
"""百思不得姐段子的爬虫"""
name = 'budejie'
start_urls = ['http://www.budejie.com/text/']
total_page = 1
def parse(self, response):
current_page = int(response.css('a.z-crt::text').extract_first())
lies = response.css('div.j-r-list >ul >li')
for li in lies:
username = li.css('a.u-user-name::text').extract_first()
content = '\n'.join(li.css('div.j-r-list-c-desc a::text').extract())
yield BudejieItem(username=username, content=content)
if current_page < self.total_page:
yield scrapy.Request(self.start_urls[0] + f'{current_page+1}')
导出到文件
利用scrapy内置的Feed功能,我们可以非常方便的将爬虫数据导出为XML、JSON和CSV等格式的文件。要做的只需要在运行scrapy的时候用-o参数指定导出文件名即可。
scrapy crawl budejie -o f.json scrapy crawl budejie -o f.csv scrapy crawl budejie -o f.xml
如果出现导出汉字变成Unicode编码的话,需要在配置中设置导出编码。
FEED_EXPORT_ENCODING = 'utf-8'
保存到MongoDB
有时候爬出来的数据并不想放到文件中,而是存在数据库中。这时候就需要编写管道来处理数据了。一般情况下,爬虫只管爬取数据,数据是否重复是否有效都不是爬虫要关心的事情。清洗数据、验证数据、保存数据这些活,都应该交给管道来处理。当然爬个段子的话,肯定是用不到清洗数据这些步骤的。这里用的是pymongo,所以首先需要安装它。
pip install pymongo
代码其实很简单,用scrapy官方文档的例子稍微改一下就行了。由于MongoDB的特性,所以这部分代码几乎是无缝迁移的,如果希望保存其他数据,只需要改一下配置就可以了,其余代码部分几乎不需要更改。
import pymongo
class BudejieMongoPipeline(object):
"将百思不得姐段子保存到MongoDB中"
collection_name = 'jokes'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'budejie')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
这个管道需要从配置文件中读取数据库信息,所以还需要在settings.py中增加以下几行。别忘了在ITEM_PIPELINES中吧我们的管道加进去。
MONGO_URI = 'mongodb://localhost:27017/'
MONGO_DATABASE = 'budejie'
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy_sample.pipelines.BudejieMongoPipeline': 2
}
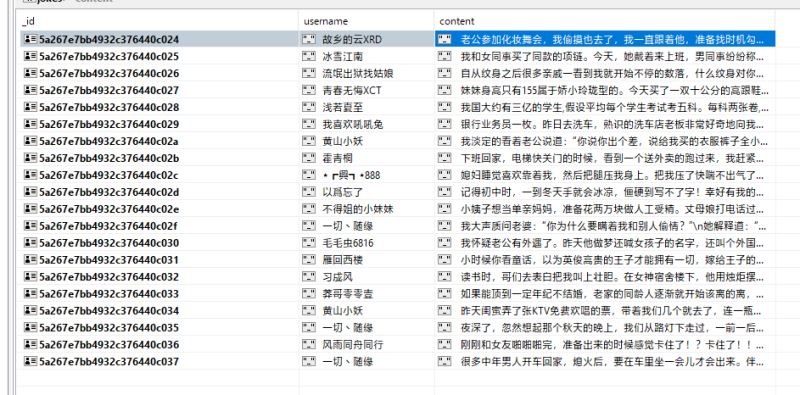
最后运行一下爬虫,应该就可以看到MongoDB中保存好的数据了。这里我用的MongoDB客户端是Studio 3T,我个人觉得比较好用的一个客户端。
scrapy crawl budejie
保存到SQL数据库
原来我基本都是用MySQL数据库,不过重装系统之后,我选择了另一个非常流行的开源数据库PostgreSQL。这里就将数据保存到PostgreSQL中。不过说起来,SQL数据库确实更加麻烦一些。MongoDB基本上毫无配置可言,一个数据库、数据集合不需要定义就能直接用,如果没有就自动创建。而SQL的表需要我们手动创建才行。
首先需要安装PostgreSQL的Python驱动程序。
pip install Psycopg2
然后建立一个数据库test和数据表joke。在PostgreSQL中自增主键使用SERIAL来设置。
CREATE TABLE joke ( id SERIAL PRIMARY KEY, author VARCHAR(128), content TEXT );
管道基本上一样,只不过将插入数据换成了SQL形式的。由于默认情况下需要手动调用commit()函数才能提交数据,于是我索性打开了自动提交。
import psycopg2
class BudejiePostgrePipeline(object):
"将百思不得姐段子保存到PostgreSQL中"
def __init__(self):
self.connection = psycopg2.connect("dbname='test' user='postgres' password='12345678'")
self.connection.autocommit = True
def open_spider(self, spider):
self.cursor = self.connection.cursor()
def close_spider(self, spider):
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
self.cursor.execute('insert into joke(author,content) values(%s,%s)', (item['username'], item['content']))
return item
别忘了将管道加到配置文件中。
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy_sample.pipelines.BudejiePostgrePipeline': 2
}
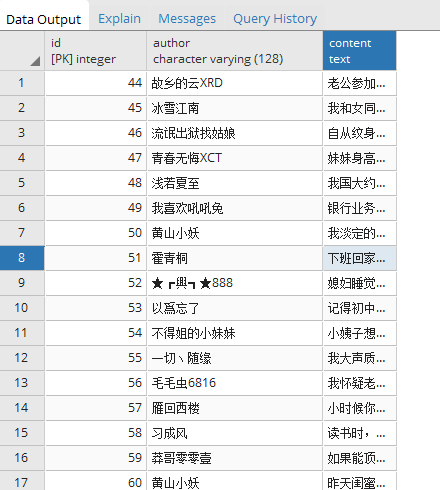
再次运行爬虫,就可以看到数据成功的放到PostgreSQL数据库中了。
以上就是抽取文本数据的例子了。虽然我只是简单的爬了百思不得姐,不过这些方法可以应用到其他方面,爬取更多更有用的数据。这就需要大家探索了。
爬美女图片
爬妹子图网站
说完了抽取文本,下面来看看如何下载图片。这里以妹子图为例说明一下。
首先定义一个图片Item。scrapy要求图片Item必须有image_urls和images两个属性。另外需要注意这两个属性类型都必须是列表,我就因为没有将image_urls设置为列表而卡了好几个小时。
class ImageItem(scrapy.Item): image_urls = scrapy.Field() images = scrapy.Field()
然后照例对网站用F12和scrapy shell这两样工具进行测试,找出爬取图片的方式。这里我只是简单的爬取一个页面的上的图片,不过只要熟悉了scrapy可以很快的修改成跨越多页爬取图片。再次提醒,爬虫中生成Item的时候切记image_urls属性是一个列表,就算只有一个URL也得是列表。
import scrapy
from scrapy_sample.items import ImageItem
class MeizituSpider(scrapy.Spider):
name = 'meizitu'
start_urls = ['http://www.meizitu.com/a/5501.html']
def parse(self, response):
yield ImageItem(image_urls=response.css('div#picture img::attr(src)').extract())
然后在配置文件中添加图片管道的设置,还需要设置图片保存位置,不然scrapy仍然会禁用图片管道。
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
IMAGES_STORE = 'images'
然后运行爬虫,就可以看到图片已经成功保存到本地了。
scrapy crawl meizitu
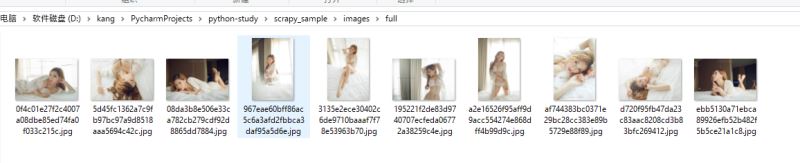
重写图片管道
从上面的图中我们可以看到文件名是一堆乱码字符,因为默认的图片管道会将图片地址做SHA1哈希之后作为文件名。如果我们希望自定义文件名,就需要自己继承图片管道并重写file_path方法。
先将默认的file_path方法贴出来。
def file_path(self, request, response=None, info=None): # check if called from image_key or file_key with url as first argument if not isinstance(request, Request): url = request else: url = request.url image_guid = hashlib.sha1(to_bytes(url)).hexdigest() # change to request.url after deprecation return 'full/%s.jpg' % (image_guid)
下面是我们的自定义图片管道,这里获取图片URL的最后一部分作为图片文件名,例如对于/123.JPG,就获取123.jpg作为文件名。
import scrapy.pipelines.images
from scrapy.http import Request
class RawFilenameImagePipeline(scrapy.pipelines.images.ImagesPipeline):
def file_path(self, request, response=None, info=None):
if not isinstance(request, Request):
url = request
else:
url = request.url
beg = url.rfind('/') + 1
end = url.rfind('.')
if end == -1:
return f'full/{url[beg:]}.jpg'
else:
return f'full/{url[beg:end]}.jpg'
如果文件名生成规则更加复杂,可以参考znns项目中的pipeline编写。他这里要根据路径生成多级文件夹保存图片,所以他的图片Item需要额外几个属性设置图片分类等。这时候就需要重写get_media_requests方法,从image_urls获取图片地址请求的时候用Request的meta属性将对应的图片Item也传进去,这样在生成文件名的时候就可以读取meta属性来确定图片的分类等信息了。
class ZnnsPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url, meta={'item': item}, headers=headers)
# 这里把item传过去,因为后面需要用item里面的书名和章节作为文件名
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
def file_path(self, request, response=None, info=None):
item = request.meta['item']
image_guid = request.url.split('/')[-1]
filename = u'full/{0[name]}/{0[albumname]}/{1}'.format(item, image_guid)
return filename
最后要说一点,如果不需要使用图片管道的几个功能,完全可以改为使用文件管道。因为图片管道会尝试将所有图片都转换成JPG格式的,你看源代码的话也会发现图片管道中文件名类型直接写死为JPG的。所以如果想要保存原始类型的图片,就应该使用文件管道。
爬取mm131网站
mm131是另一个图片网站,为什么我要说这个网站呢?因为这个网站使用了防盗链技术。对于妹子图网站来说,由于它没有防盗链功能,所以我们从HTML中获取的图片地址就是实际的图片地址。但是对于有反盗链的网站来说,当你顺着图片URL去下载图片的时候,会被重定向到一个无关的图片。因为这个原因,另外浏览器有缓存机制导致我直接访问图片地址的时候会先返回缓存的图片,导致我浪费好几个小时。最后我刷新浏览器的时候才发现原来被重定向了。
对于这种情况,需要我们研究怎样才能访问到图片。使用Scrapy框架时 普通反爬虫机制的应对策略这篇文章列举了一些常见的策略。我们要做的就是根据这些策略进行尝试。现在我用的是火狐浏览器,它的F12工具很好用,其中有一个编辑和重发功能可以方便的帮助我们定位问题。
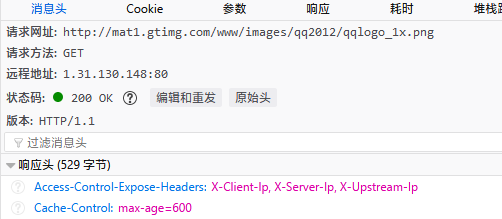
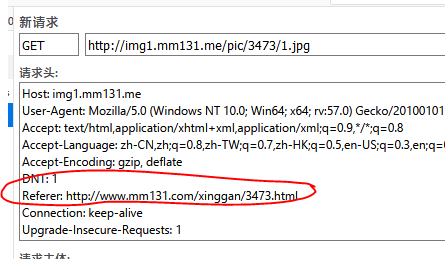

在上面几张图中,我们可以看到直接尝试访问图片会得到302,然后被重定向到一个腾讯logo上。但是在添加了Referer之后,成功获得了图片。所以问题就是Referer了。这里简单介绍一下Referer,它其实是Referrer的误拼写。当我们从一个页面点击进入另一个页面时,后者的Referer就是前者。所以有些网站就利用Referer做判断,如果检测是由另一个网页进来的,那么正常访问,如果直接访问图片等资源没有Referer,就判断为爬虫,拒绝请求。这种情况下的解决办法也很简单,既然网站要Referer,我们手动加上不就行了吗。
首先,对于图片Item,新增一个referer字段,用于保存该图片的Referer。
class ImageItem(scrapy.Item): image_urls = scrapy.Field() images = scrapy.Field() referer = scrapy.Field()
然后在爬虫里面,抓取图片实际地址的时候,同时设置当前网页作为Referer。
import scrapy
from scrapy_sample.items import ImageItem
class Mm131Spider(scrapy.Spider):
name = 'mm131'
start_urls = ['http://www.mm131.com/xinggan/3473.html',
'http://www.mm131.com/xinggan/2746.html',
'http://www.mm131.com/xinggan/3331.html']
def parse(self, response):
total_page = int(response.css('span.page-ch::text').extract_first()[1:-1])
current_page = int(response.css('span.page_now::text').extract_first())
item = ImageItem()
item['image_urls'] = response.css('div.content-pic img::attr(src)').extract()
item['referer'] = response.url
yield item
if response.url.rfind('_') == -1:
head, sep, tail = response.url.rpartition('.')
else:
head, sep, tail = response.url.rpartition('_')
if current_page < total_page:
yield scrapy.Request(head + f'_{current_page+1}.html')
最后还需要重写图片管道的get_media_requests方法。我们先来看看图片管道基类中是怎么写的。self.images_urls_field在这几行前面设置的,scrapy会尝试先从配置文件中读取自定义的图片URL属性,获取不到就使用默认的。然后在用图片URL属性从item中获取url,然后传递给Request构造函数组装为一个Request列表,后续下载器就会用这些请求来下载图片。
def get_media_requests(self, item, info): return [Request(x) for x in item.get(self.images_urls_field, [])]
恰好我们要做的事情很简单,就是遍历一遍这个Request列表,在每个Request上加上Referer请求头就行了。所以实际上代码超级简单。我们调用基类的实现,也就是上面这个,然后遍历一边再返回即可。
class RefererImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
requests = super().get_media_requests(item, info)
for req in requests:
req.headers.appendlist("referer", item['referer'])
return requests
最后启用这个管道。
ITEM_PIPELINES = {
# 'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy_sample.pipelines.RefererImagePipeline': 2
}
运行一下爬虫,这次可以看到,成功下载到了一堆图片。
scrapy crawl mm131
当然你也可以关掉这个管道,然后运行看看,会发现终端里一堆重定向错误,无法下载图片。
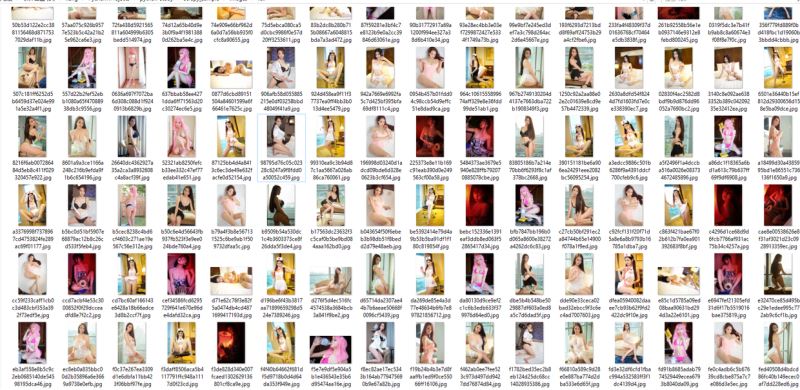
这仅仅是一个例子,实际上很多网站可能综合使用多种技术来检测爬虫,这样我们的爬虫也需要多种办法结合来反爬虫。这个网站恰好只使用了Referer,所以我们只用Referer就能解决。
备份CSDN上所有文章
最后一个例子就来爬取CSDN上所有文章,其实在我的scrapy练习中很早就有一个简单的例子,不过那个是在未登录的情况下获取所有文章的名字和链接。这里我要做的是登录CSDN账号,然后把所有文章爬下来保存成文件,也就是演示一下如何用scrapy模拟登录过程。
为什么要选择CSDN呢?其实也很简单,因为现在POST明文用户名和密码还不需要验证码就能登录的网站真的不多了啊!当然用CSDN的同学也不用怕,虽然CSDN传递的是明文密码,但是由于使用了HTTPS,所以安全性还是可以的。
翻了翻以前写的文章,发现我确实写过模拟CSDN登录的文章Python登录并获取CSDN博客所有文章列表,不过运行了一下我发现CSDN页面经过改版,有些地方变了,所以还是需要重新研究一下。需要注意HTTPS传输是不会出现在浏览器F12工具中的,只有HTTP传输才能在工具中捕获。所以这时候需要用Fiddler来研究。
不过实际上我又研究了半天,发现其实CSDN登录过程没变化,我只要把原来写的一个多余的验证函数删了马上又可以正常运行了……这里是我原来的CSDN模拟登录代码,用BeautifulSoup4和requests写的。
又耗费了几个小时终于把这个爬虫写完了,其实编码过程真的没费多少时间。主要是由于我对Python语言还是属于速成的,很多细节没掌握。比方说scrapy如何用回调方法来分别解析不同页面、回调方法如何传递数据、写文件的时候没有检查目录是否存在、文件应该用什么模式写入、如何以UTF-8编码写文件、目录分隔符如何处理等等,其实都是一些小问题,不过一个一个解决真的废了我不少事情。
首先,照例定义一个Item,因为我只准备简单下载文章,所以只需要标题和内容两个属性即可,标题会作为文件名来使用。
class CsdnBlogItem(scrapy.Item): title = scrapy.Field() content = scrapy.Field()
然后是爬虫本体,这是我目前写过的最复杂的一个爬虫,确实费了不少时间。这个爬虫跨越了多个页面,还要针对不同页面解析不同的数据。不过虽然看着复杂,其实倒是也很简单。首先是初始方法,从命令行获取CSDN登录用户名和密码,然后存起来备用。由于需要用户登录,所以parse方法的作用就从解析页面变成了用户登录。具体登录过程在我原来那篇文章中详细解释过了。这里就是简单的利用FormRequest.from_response方法将用户名、密码以及页面中的隐藏表单域一起提交。需要注意的就是callback参数,它表示页面返回的请求会有另一个方法来处理。
然后是redirect_to_articles方法,本来浏览器登录成功的话,会返回一个重定向页面,浏览器会执行其中的JS代码重定向到CSDN页面。不过我们这是爬虫,完全没有执行JS代码的功能。实际上我们也完全不用在意这个重定向过程,既然登陆成功,有了Cookie,我们想访问什么页面都可以。所以这里同样直接生成一个新请求访问文章页面,然后用callback参数指定get_all_articles作为回调。
从get_all_articles方法开始,我们就开始解析页面了。这个方法首先查询总共有多少页,而且由于csdn服务器是REST形式的,所以我们可以直接将文章页面基地址和文章页数拼起来生成所有的页面。在这些页面中,每一页上都有一些文章链接,我们点进去就能访问实际文章了。生成所有页面的链接之后,我们同样设置回调,将这些页面交给parse_article_links方法处理。
import scrapy
from scrapy import FormRequest
from scrapy import Request
from scrapy_sample.items import CsdnBlogItem
class CsdnBlogBackupSpider(scrapy.Spider):
name = 'csdn_backup'
start_urls = ['https://passport.csdn.net/account/login']
base_url = 'http://write.blog.csdn.net/postlist/'
get_article_url = 'http://write.blog.csdn.net/mdeditor/getArticle?id='
def __init__(self, name=None, username=None, password=None, **kwargs):
super(CsdnBlogBackupSpider, self).__init__(name=name, **kwargs)
if username is None or password is None:
raise Exception('没有用户名和密码')
self.username = username
self.password = password
def parse(self, response):
lt = response.css('form#fm1 input[name="lt"]::attr(value)').extract_first()
execution = response.css('form#fm1 input[name="execution"]::attr(value)').extract_first()
eventid = response.css('form#fm1 input[name="_eventId"]::attr(value)').extract_first()
return FormRequest.from_response(
response,
formdata={
'username': self.username,
'password': self.password,
'lt': lt,
'execution': execution,
'_eventId': eventid
},
callback=self.redirect_to_articles
)
def redirect_to_articles(self, response):
return Request(CsdnBlogBackupSpider.base_url, callback=self.get_all_articles)
def get_all_articles(self, response):
import re
text = response.css('div.page_nav span::text').extract_first()
total_page = int(re.findall(r'共(\d+)页', text)[0])
for i in range(1, total_page + 1):
yield Request(CsdnBlogBackupSpider.base_url + f'0/0/enabled/{i}', callback=self.parse_article_links)
def parse_article_links(self, response):
article_links = response.xpath('//table[@id="lstBox"]/tr[position()>1]/td[1]/a[1]/@href').extract()
last_index_of = lambda x: x.rfind('/')
article_ids = [link[last_index_of(link) + 1:] for link in article_links]
for id in article_ids:
yield Request(CsdnBlogBackupSpider.get_article_url + id, callback=self.parse_article_content)
def parse_article_content(self, response):
import json
obj = json.loads(response.body, encoding='UTF8')
yield CsdnBlogItem(title=obj['data']['title'], content=obj['data']['markdowncontent'])
在parse_article_links方法中,我们获取每一页上的所有文章,将文章ID抽出来,然后和这个地址'http://write.blog.csdn.net/mdeditor/getArticle?id='拼起来。这是我编辑CSDN文章的时候从浏览器中抓出来的一个地址,它会返回一个JSON字符串,包含文章标题、内容、Markdown文本等各种信息。同样地,我们用parse_article_content回调函数来处理这个新请求。
下面就是最后一步了,在parse_article_content方法中做的事情很简单,将JSON字符串转换成Python对象,然后把我们需要的属性拿出来。需要交给管道处理的Item对象,也是在这最后一步生成。当然除了用这么多回调函数来处理,我们还可以在一个函数中手动生成请求并处理响应。
这种通过多个回调函数来处理请求的方式,在编写复杂的爬虫中是很常见的。例如我们要爬一个美女图片网站,这个网站中每个美女都有好几个图集,每个图集有好几页,每页好几张图。如果我们希望按照分类和图集来生成目录并保存,那么不仅需要多个回调函数来爬取,还需要将图集、分类等信息跨越多个回调函数传递给最终生成Item的函数。这时候需要利用Request构造函数中的meta属性,这里是一个例子,具体代码大家自己看就行了。
最后就是文章保存管道了。这里没什么技术难点,不过让我这个以前没弄过这玩意的人来写,确实费了不少功夫。首先检测目录是否存在,如果不存在则创建之。假如目录不存在的话,open函数就会失败。然后就是用UTF8编码保存文章。
class CsdnBlogBackupPipeline(object):
def process_item(self, item, spider):
dirname = 'blogs'
import os
import codecs
if not os.path.exists(dirname):
os.mkdir(dirname)
with codecs.open(f'{dirname}{os.sep}{item["title"]}.md', 'w', encoding='utf-8') as f:
f.write(item['content'])
f.close()
return item
最后别忘了在配置文件中启用管道。
ITEM_PIPELINES = {
# 'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy_sample.pipelines.CsdnBlogBackupPipeline': 2
}
然后运行一下爬虫,注意这个爬虫需要接受额外的用户名和密码参数,我们使用-a参数来指定。
scrapy crawl csdn_backup -a username="用户名" -a password="密码"
这里说一下,我现在改为使用简书来编写文章,一来是由于简书的体验确实相比来说非常好,在编辑器中可以直接粘贴并自动上传剪贴板中的图片;二来因为简书图片没有外链限制,所以Markdown文本可以直接复制到其他网站中,同时维护多个博客非常容易,如果有同时关注我CSDN和简书的同学也会发现,很多文章我的提交时间基本只差了十几秒,这就是复制粘贴所用的时间。包括刚刚爬下来的文章,只要在Markdown编辑器中打开,图片都可以正常访问。
以上就是我备份CSDN上文章的一个简单例子,说它简单因为真的没干什么事情,单纯的把文章内容爬下来而已,其中的图片存储仍然依赖于简书和其他网站来保存。有兴趣的同学可以尝试做更完善的备份功能,将每篇文章按目录保存,文章中的图片按照各自的目录下载到本地,并将Markdown文本中对应图片的地址由服务器替换为本地路径。把这些功能全做完,就是一个真正的文章备份工具了。由于水平所限,我就不做了。
总结
这篇文章到这里也该结束了,虽然只有4个例子,但是我尝试涵盖爬虫的所有应用场景、爬取图片、爬取文本、保存到数据库和文件、自定义管道等等。
以上就是本文关于scrapy爬虫实例分享的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!