yipeiwu_com6年前
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import Beautiful...
yipeiwu_com6年前
get请求 简单使用 import requests ''' 想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载! ''...
yipeiwu_com6年前
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个s...
yipeiwu_com6年前
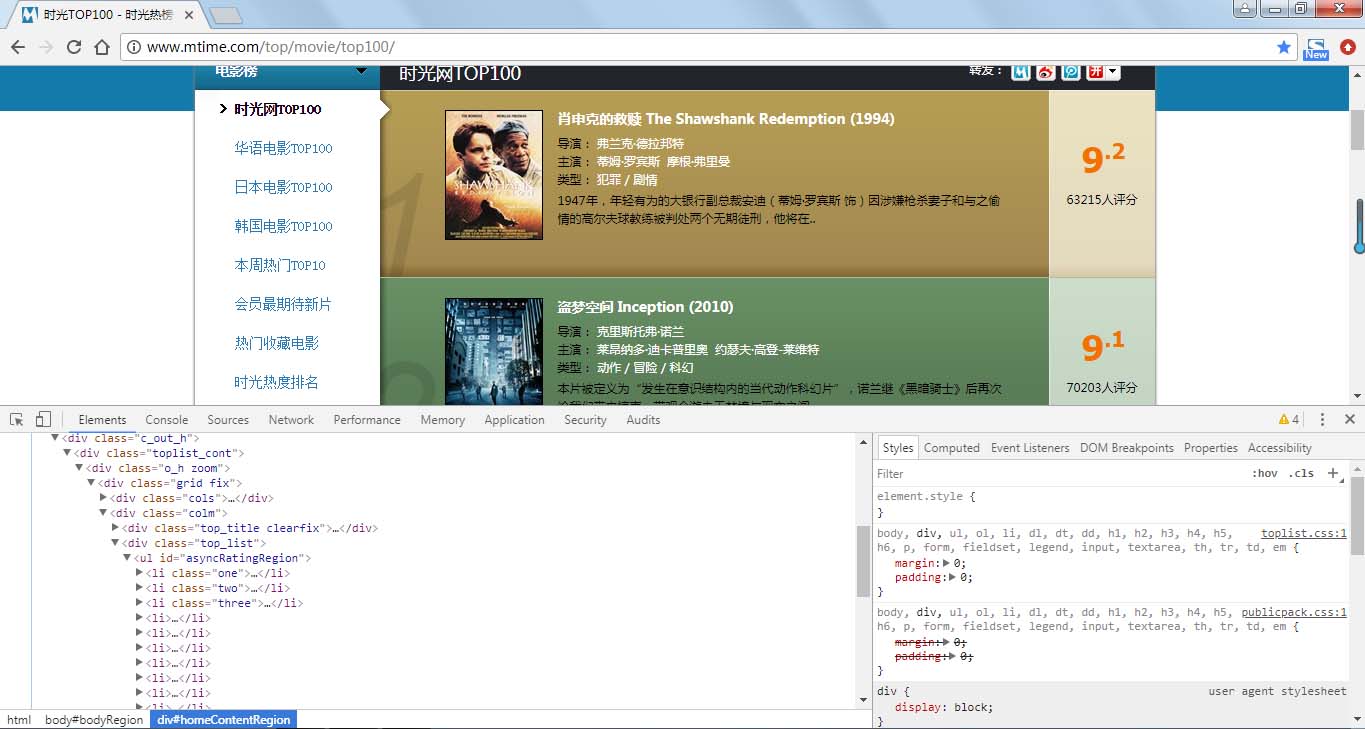
前言 上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢。本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快。 本次爬取的豆...
yipeiwu_com6年前
前言 还有一年多就要毕业了,不准备考研的我要着手准备找实习及工作了,所以一直没有更新。 因为Python是自学不久,发现很久不用的话以前学过的很多方法就忘了,今天打算使用简单的Beaut...
yipeiwu_com6年前
用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*- import re import urllib2 from bs4import Bea...
yipeiwu_com6年前
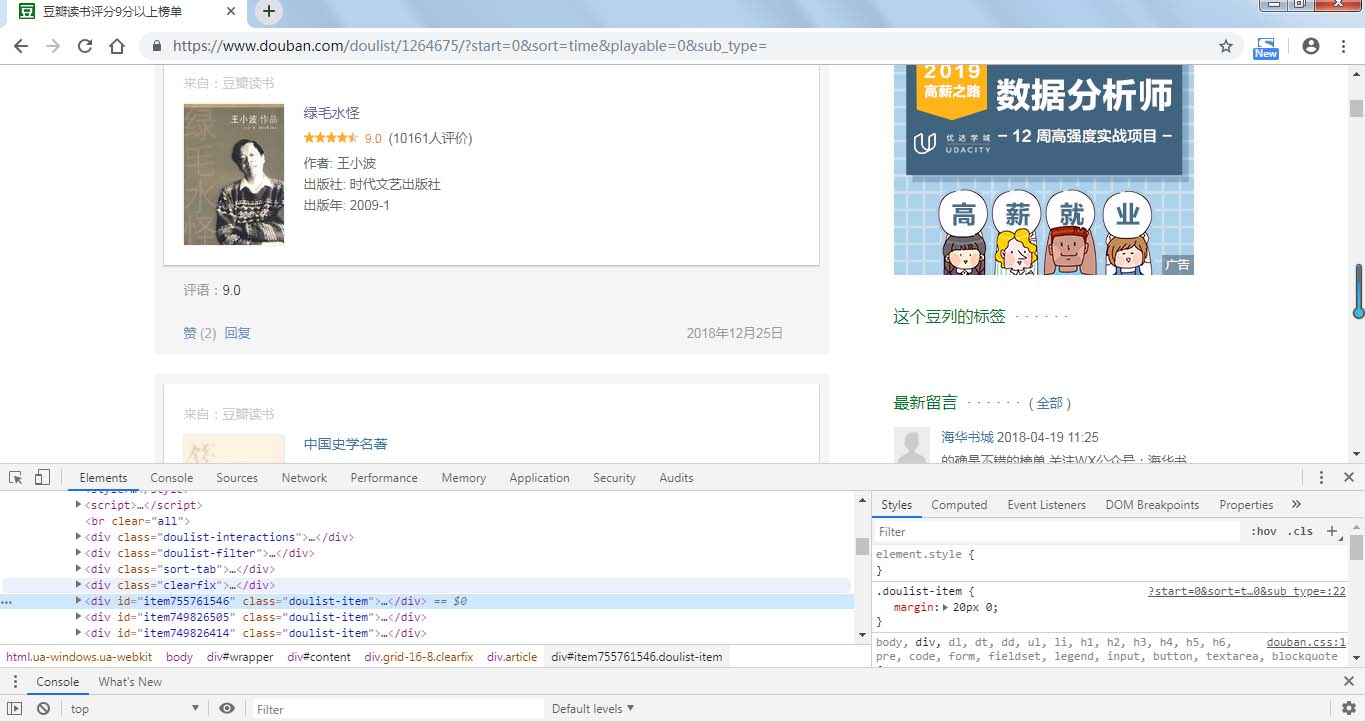
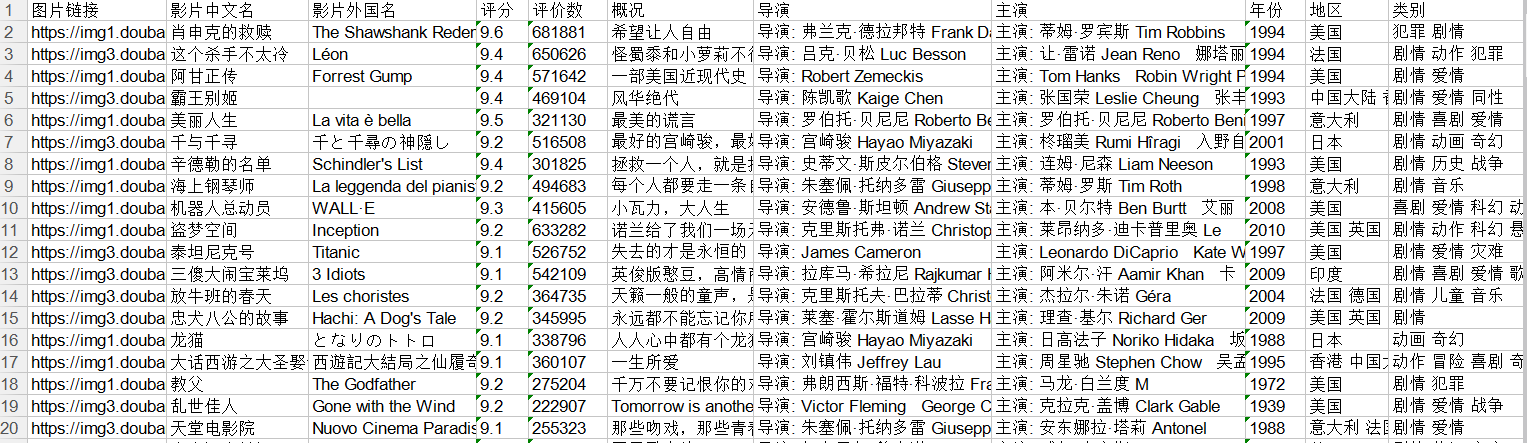
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入...
yipeiwu_com6年前
介绍 本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源,后面的代码只是贴出了核心...
yipeiwu_com6年前
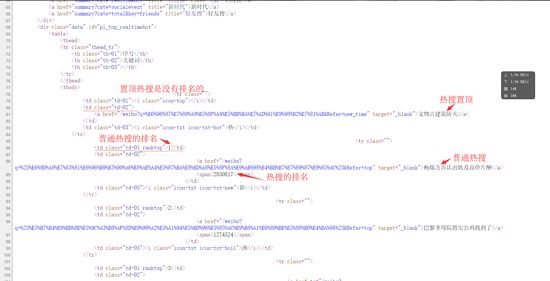
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1...
yipeiwu_com6年前
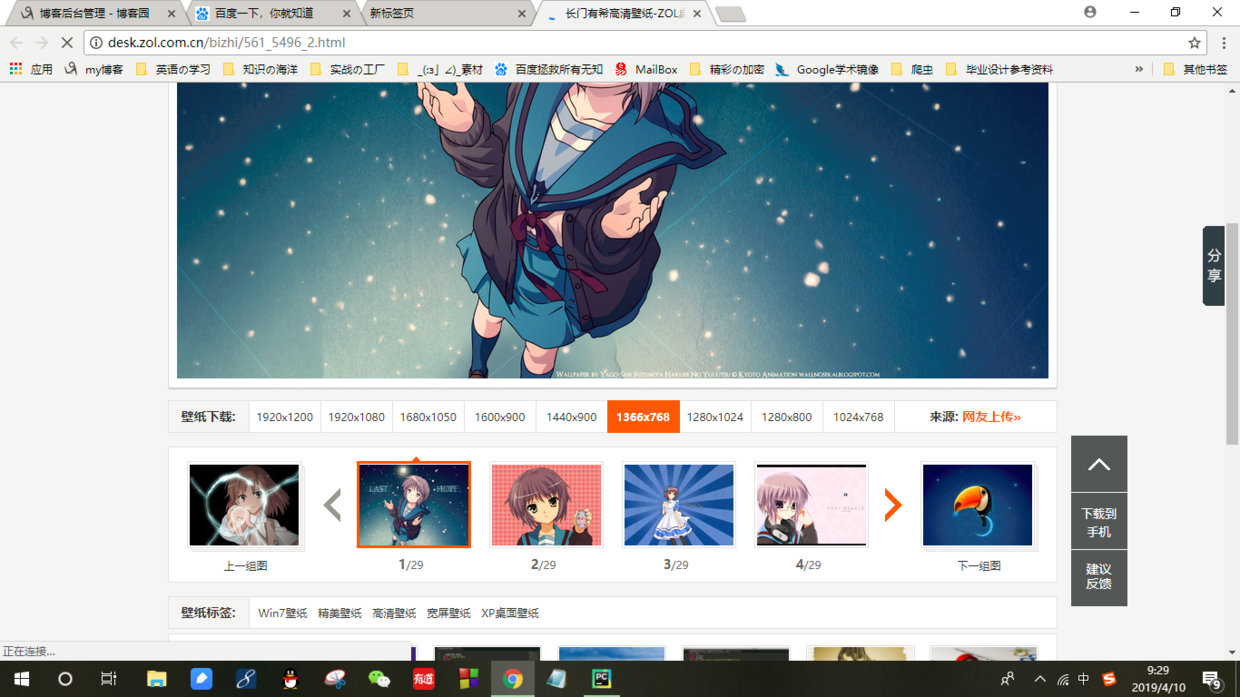
前言 在设计爬虫项目的时候,首先要在脑内明确人工浏览页面获得图片时的步骤 一般地,我们去网上批量打开壁纸的时候一般操作如下: 1、打开壁纸网页 2、单击壁纸图(打开指定壁纸的页面) 3、...