详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤
pycharm是无法创建一个scrapy项目的

因此,我们需要用命令行的方法新建一个scrapy项目
请确保已经安装了scrapy,twisted,pypiwin32
一:进入你所需要的路径,这个路径存储你创建的项目
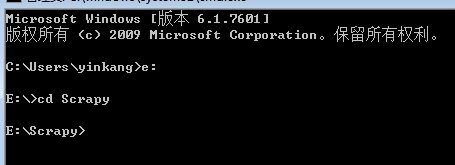
我的将放在E盘的Scrapy目录下
二:创建项目:scrapy startproject ***(这个是项目名)

这样就创建好了一个名为tencent的项目
三:进入项目新建一个爬虫:scrapy genspider tencent_spider hr.tencent.com
这里我们要注意,上面的命令,加黑的是爬虫名称,斜体是域名

这样,我们就新建了一个爬虫项目,打开文件夹查看
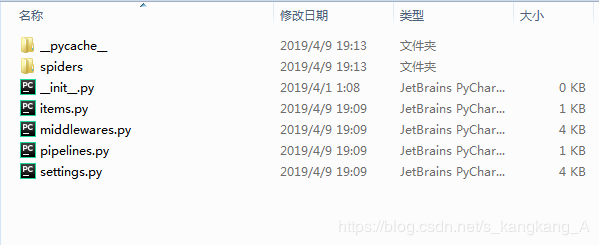
打开spiders

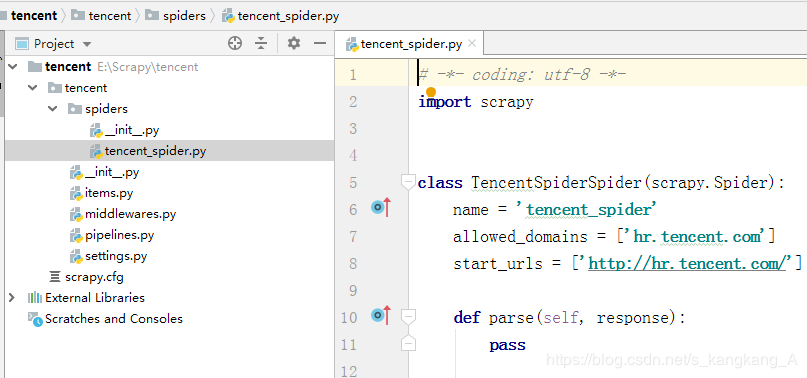
然后我们用pycharm打开

点击File —>open,找到项目所在文件夹,打开即可
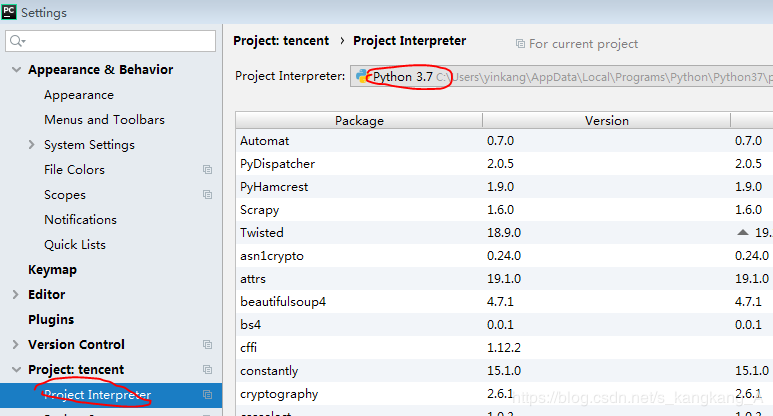
这样,我们就新建了一个scrapy项目,如果安装了所需要的库,scrapy飘红,记得去切换解释器
在File—>settings的标红的地方
另外推荐大家,在根目录下新建一个start.py的文件并写入
from scrapy import cmdline
cmdline.execute("scrapy crawl tencent_spider".split())
这样,我们每次运行,运行start.py,即可,不用到命令行执行运行命令
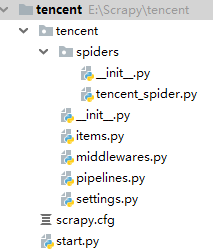
鼠标右键tencent,新建python文件,即可创建。
以上所述是小编给大家介绍的python3 Scrapy爬虫创建项目详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!