yipeiwu_com6年前
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 该方法是依赖于urllib2库来完成的,首先你需要安装好你的python环境,然后安装urllib...
yipeiwu_com6年前
在爬虫的过程中,我们经常会遇见很多网站采取了防爬取技术,或者说因为自己采集网站信息的强度和采集速度太大,给对方服务器带去了太多的压力。 如果你一直用同一个代理ip爬取这个网页,很有可能i...
yipeiwu_com6年前
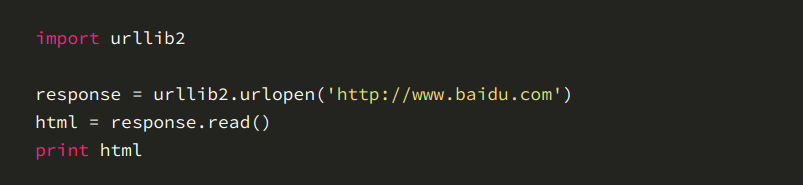
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它。现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首...
yipeiwu_com6年前
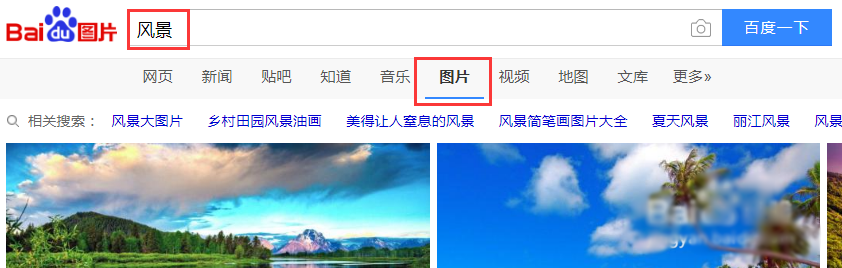
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等。怎样通过Python爬虫把这些资源下载下来。 1、怎样在网上找资源: 就是百度图片为例,当你如下图在百度图片里搜...
yipeiwu_com6年前
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言...
yipeiwu_com6年前
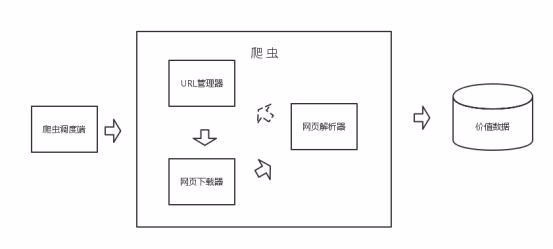
爬虫具有域名切换、信息收集以及信息存储功能。 这里讲述如何构建基础的爬虫架构。 1、urllib库:包含从网络请求数据、处理cookie、改变请求头和用户处理元数据的函数。是python...
yipeiwu_com6年前
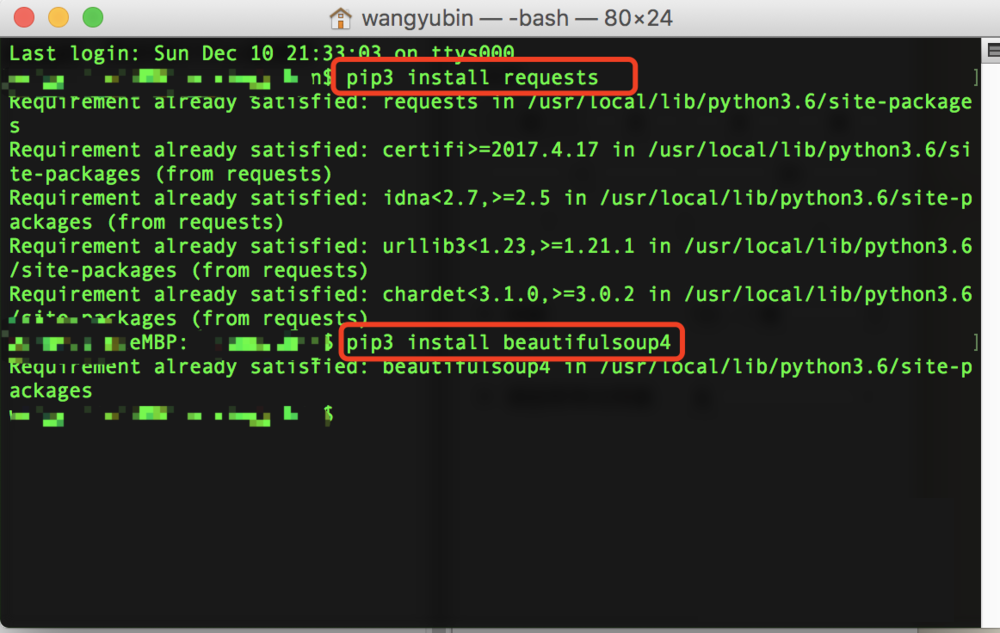
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windo...
yipeiwu_com6年前
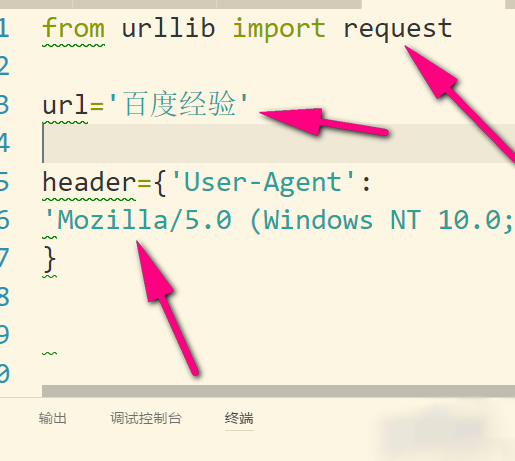
写一个爬虫首先就是学会设置请求头header,这样才可以伪装成浏览器。下面小编我就来给大家简单分析一下python3怎样构建一个爬虫的请求头header。 1、python3跟2有了细微...
yipeiwu_com6年前
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现获取动态gif格式搞笑图片的方法。分享给大家供大家参考,具体如下: 有时候看到一些喜欢的动图,如果一个个取保存挺麻烦,有的网站还不支持右键保存,因此使用...