Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验。(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到)

1、划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数。代理可以根据自己需要选择,当然免费的也是有的,但是可用率可想而知的。(飞猪IP)
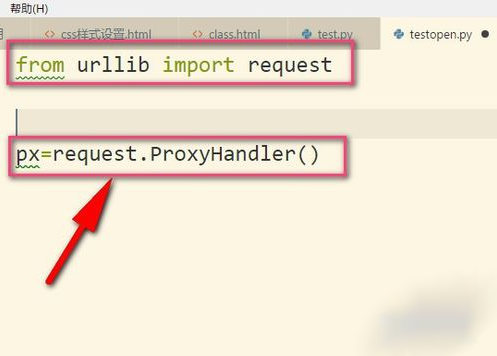
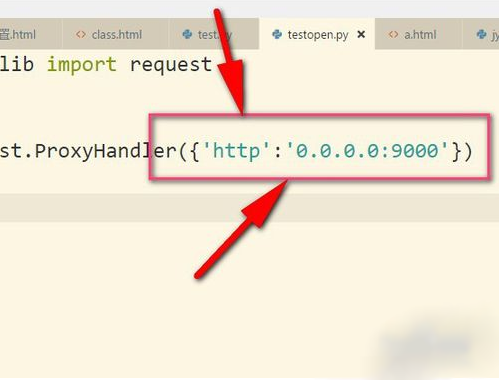
2、接着把IP地址以字典的形式放入其中,这个IP地址是我乱写的,只是用来举例。设置键为http,当然有些是https的,然后后面就是IP地址以及端口号(9000),具体看你的IP地址是什么类型的,不同IP端口号可能不同根据你在飞猪提取的端口为准。
3、接着再用build_opener()来构建一个opener对象。
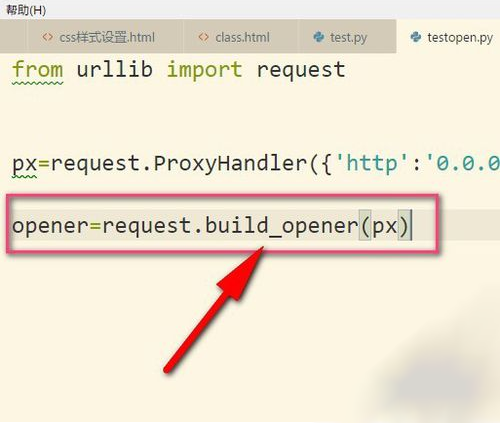
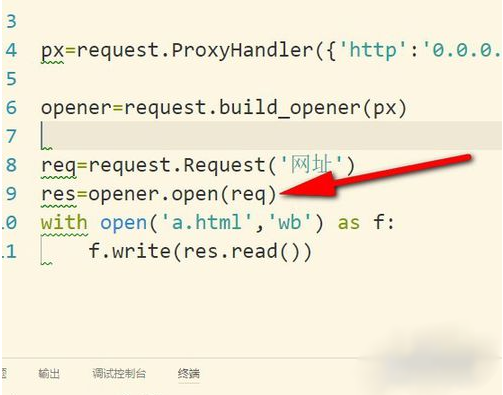
4、然后调用构建好的opener对象里面的open方法来发生请求。实际上urlopen也是类似这样使用内部定义好的opener.open(),这里就相当于我们自己重写。
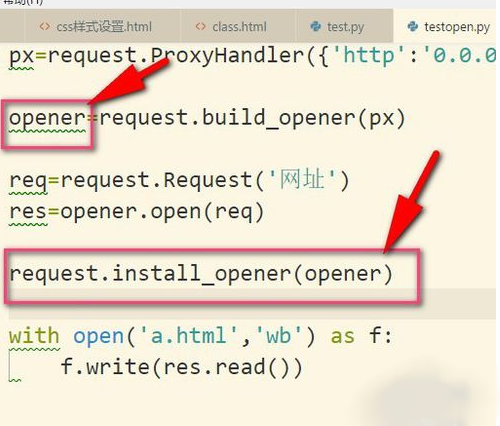
5、当然了,如果我们使用install_opener(),就可以把之前自定义的opener设置成全局的。
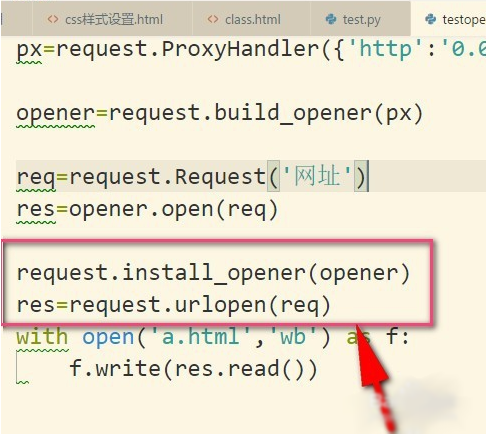
6、设置成全局之后,如果我们再使用urlopen来发送请求,那么发送请求使用的IP地址就是代理IP,而不是本机的IP地址了。
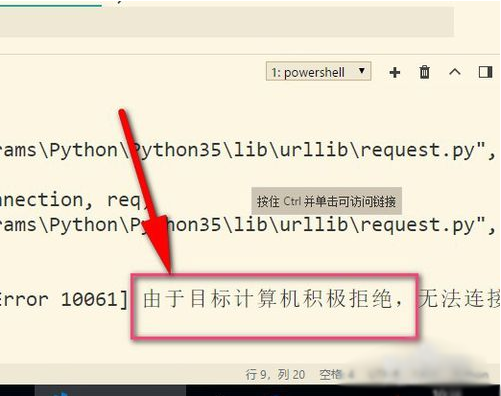
7、最后再来说说使用代理遇到的错误,提示目标计算机积极拒绝,这就说明可能是代理IP无效,或者端口号错误,这就需要使用有效的IP才行哦。(这边现在是乱填写的IP地址)可选择飞猪的代理IP。
总结:以上就是本次关于Python数据抓取爬虫代理防封IP方法,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。