python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻
1、大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现
2、首先,我们要写爬虫,可以借鉴一些工具,我们先从简单的入门,首先说到请求,我们就会想到python中,非常好用的requests,然后说到分析解析就会用到bs4,然后我们可以直接用pip命令来实现安装,假如安装的是python3,也可以用pip3
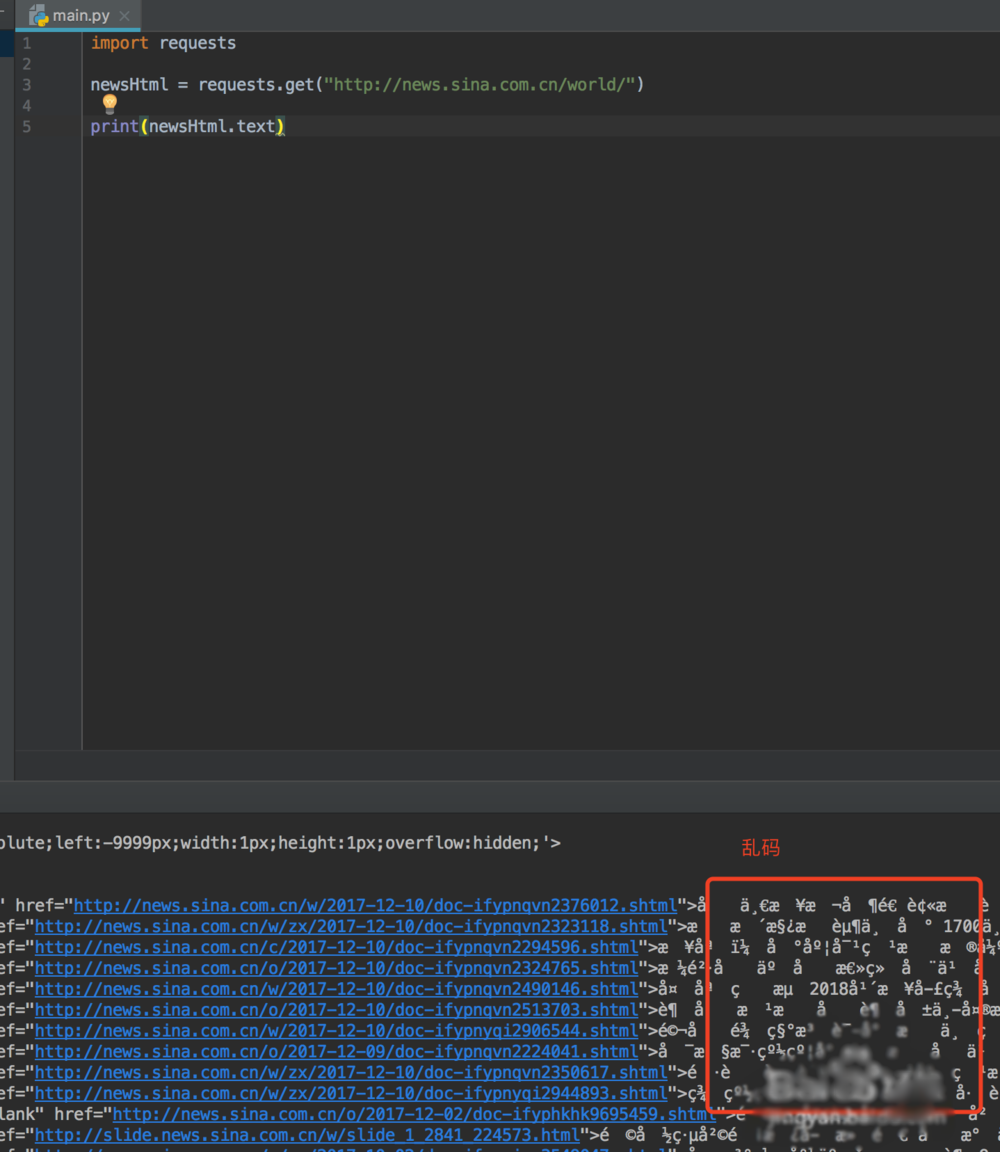
3、安装好这两个类库之后,然后我们就可以先请求数据,查看下新闻的内容,这个时候我们有可能看到的是乱码
4、怎么处理乱码呢?我们可以拿浏览器打开网页,右键查看网页源代码,我们可以看到编码格式为utf-8
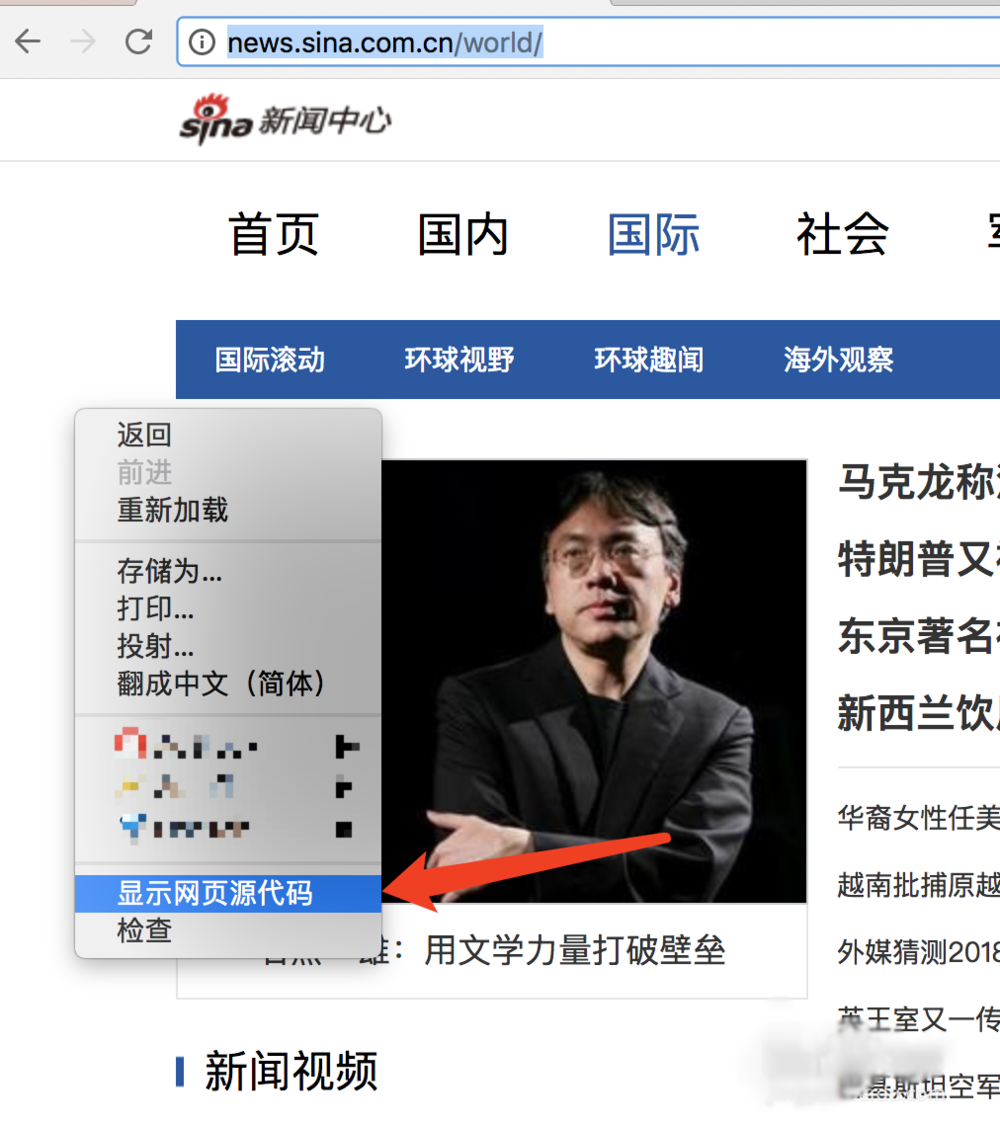
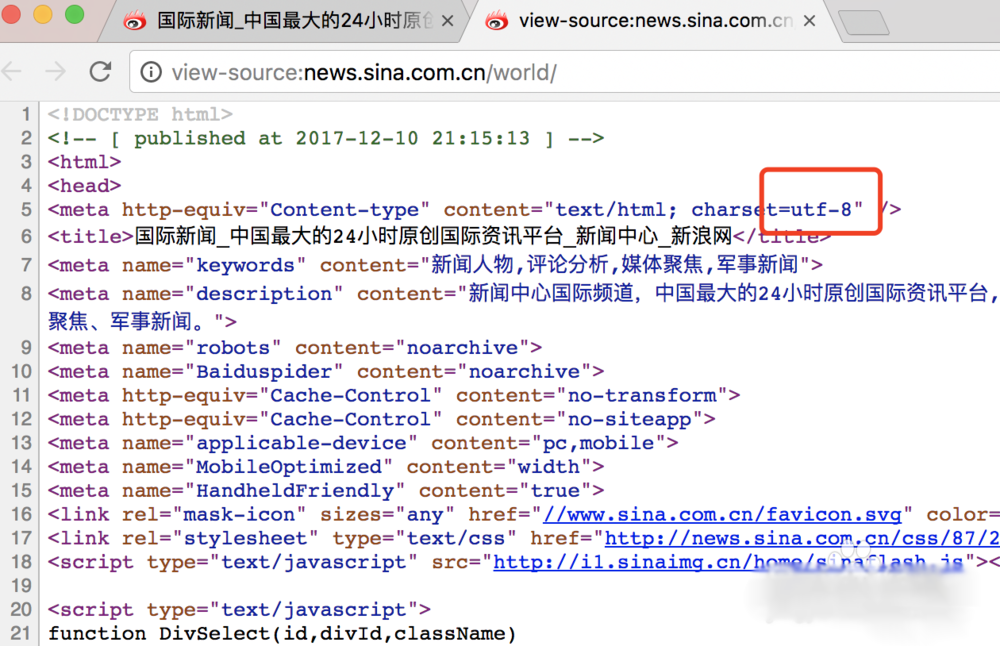
5、然后我们在输出的时候添加编码格式,就可以查看到正确编码的数据了
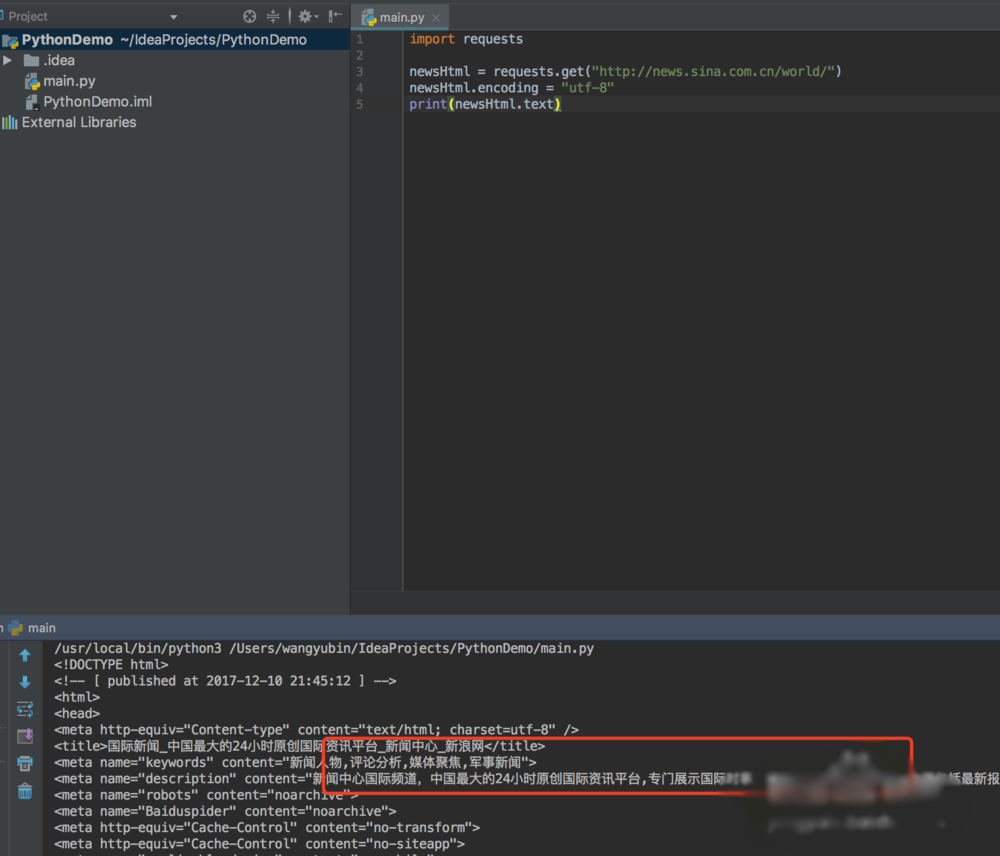
6、拿到数据之后,我们需要先分析数据,看我们想要的数据在哪里,我们打开浏览器,右键审查,然后按示例图操作,就可以看到我们新闻所在的标签,假如是windows系统,选择开发中工具里面一样
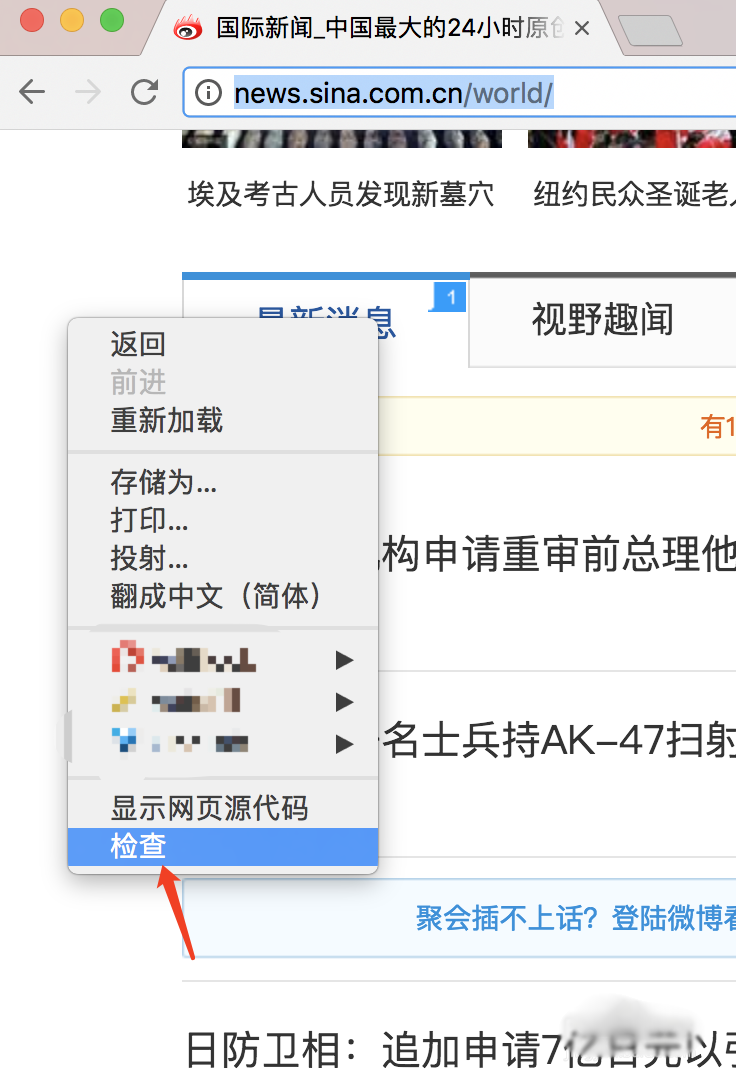
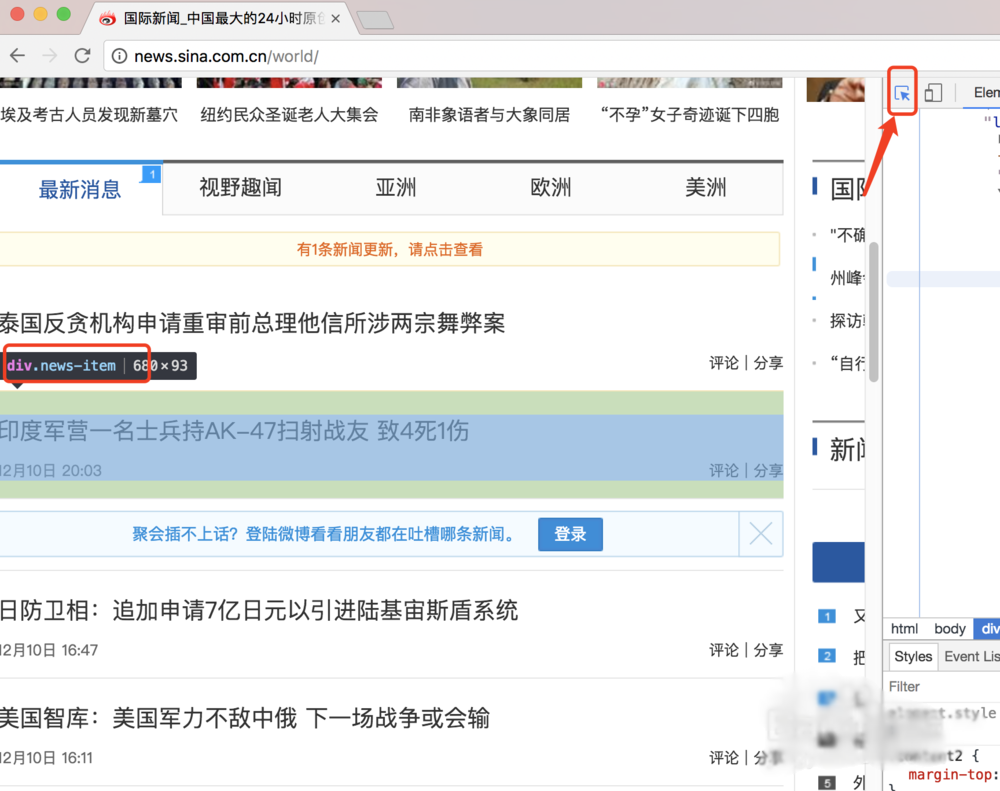
7、我们知道属于哪个标签之后,就是用bs4来解析拿到我们想要的数据了
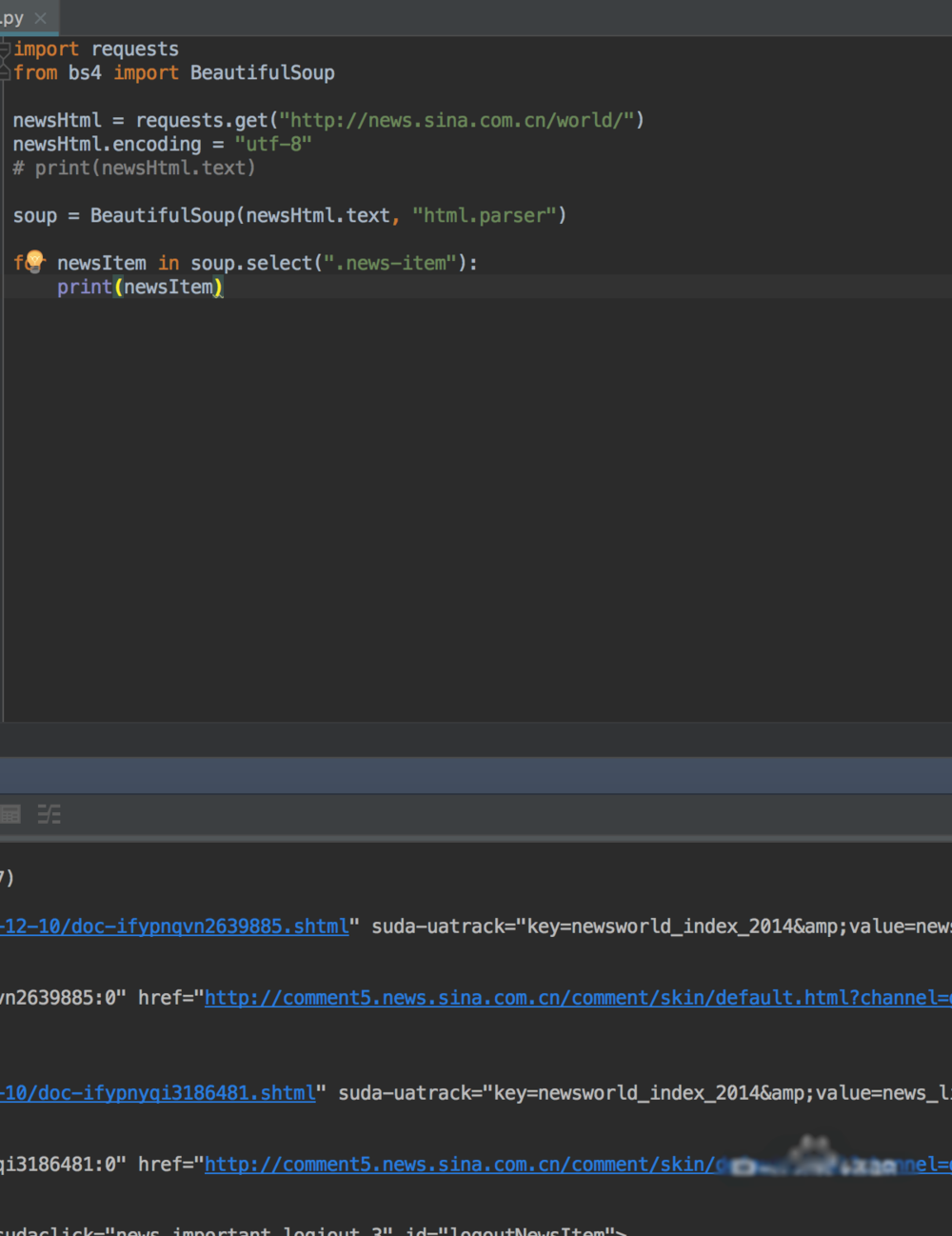
8、我们想要拿到新闻的具体标题,时间,地址,就需要我们在对元素进行深入的解析,我们还是按之前的方法,找到标题所在的标签
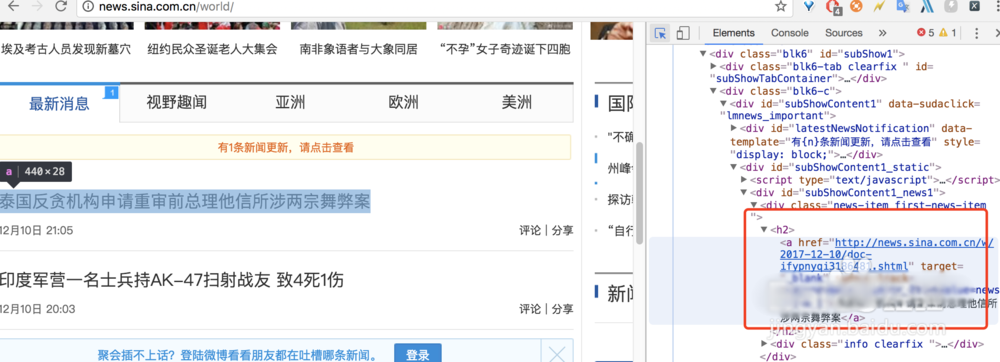
9、然后我们编写标题时间地址的python程序,就可以爬取出对应的标题内容,时间和地址
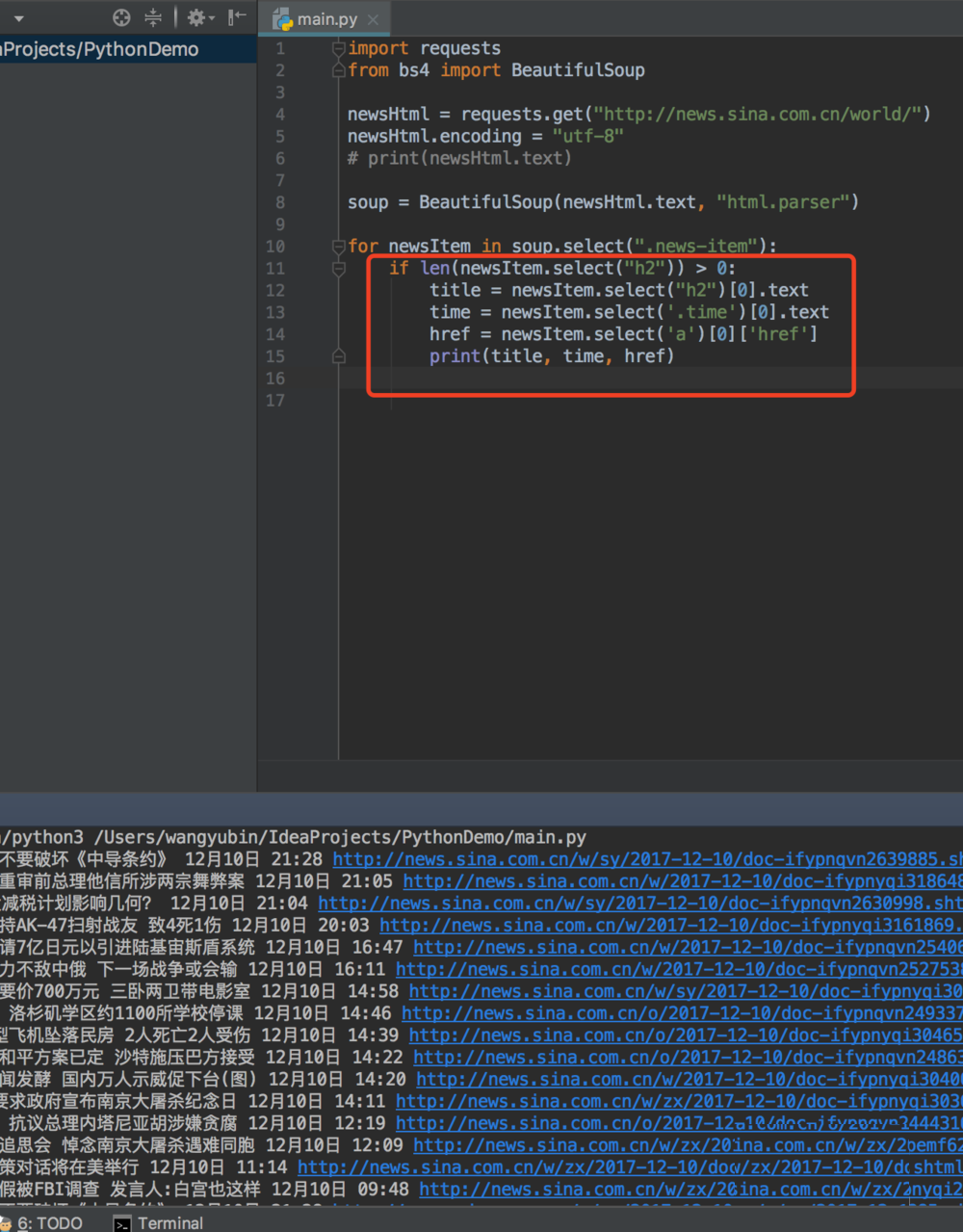
10、简单的python爬取新闻就讲到这里啦
总结:以上就是关于Python爬虫获取新浪新闻内容的步骤,感谢大家的的阅读和对【听图阁-专注于Python设计】的支持。