python3爬虫怎样构建请求header
写一个爬虫首先就是学会设置请求头header,这样才可以伪装成浏览器。下面小编我就来给大家简单分析一下python3怎样构建一个爬虫的请求头header。
1、python3跟2有了细微差别,所以我们先要引入request,python2没有这个request哦。然后复制网址给url,然后用一个字典来保存header,这个header怎么来的?看第2步。
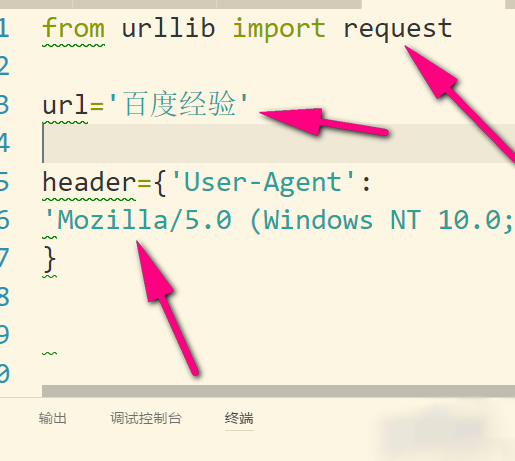
2、打开任意浏览器某一页面(要联网),按f12,然后点network,之后再按f5,然后就会看到“name”这里,我们点击name里面的任意文件即可。
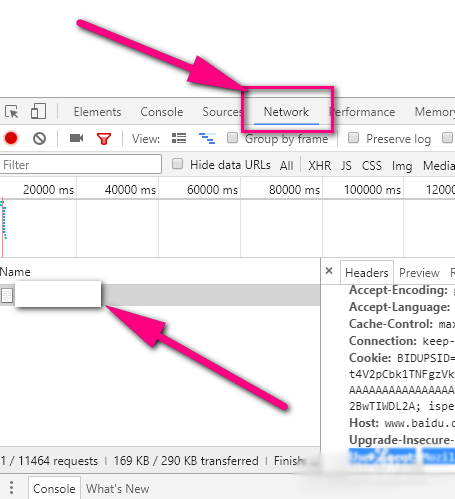
3、之后右边有一个headers,点击headers找到request headers,这个就是浏览器的请求报头了。
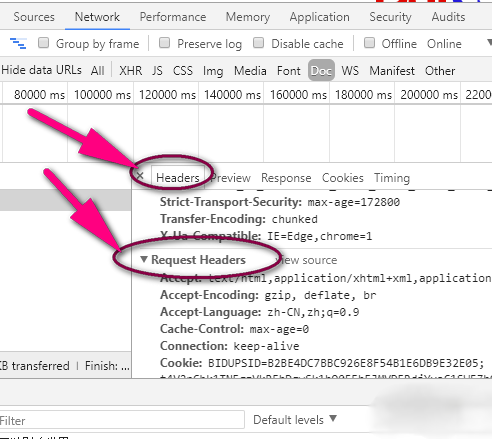
4、然后复制其中的user-agent,其他的cookie还有Accept可以要也可以不要,主要是伪装成浏览器,所以我就用了user-agent

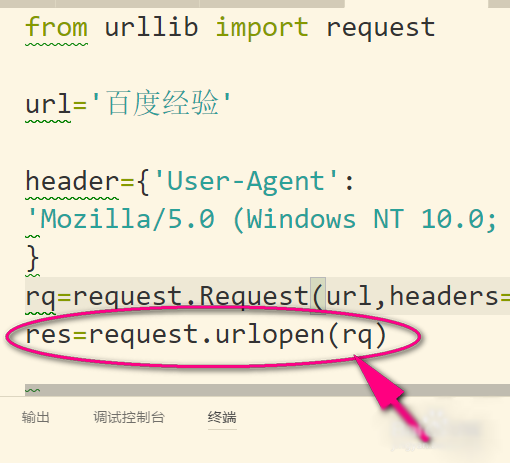
5、接着再用Request方法把url和headers组合在一起就可以构造一个比较简单的请求了。Request有三个参数(url,data,headers),如果有使用data就是post请求了,没有就是get请求。这里我没有data,所以我就指定headers=header,不然header就会被当成data了。
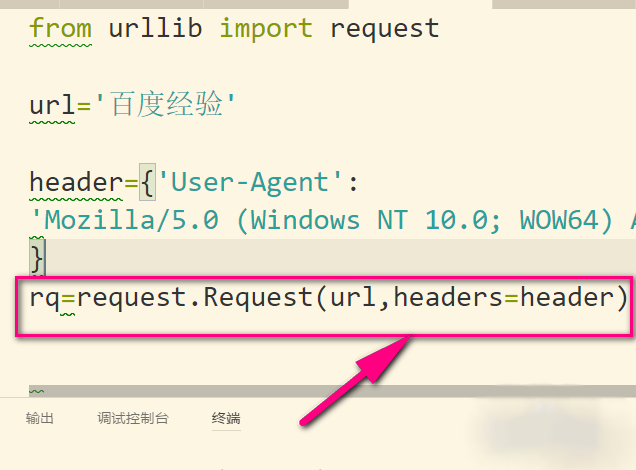
6、请求对象rq就构造好了,然后用urlopen发送这个请求对象就可以了。这就是简单的请求头设置了。
总结:以上就是关于python3爬虫怎样构建请求头的相关知识点,感谢大家的阅读和对【听图阁-专注于Python设计】的支持。