python爬虫获取百度首页内容教学
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它。现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首页信息。
1、首先我们创建一个urllib2_test01.py,然后输入以下代码:
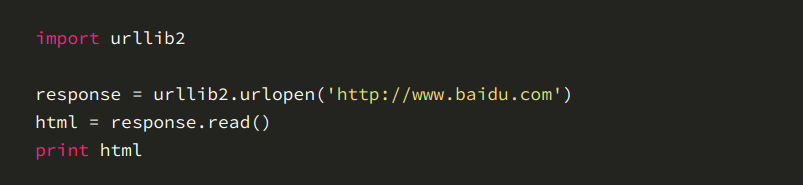
2、最简单的获取一个url的信息代码居然只需要4行,执行写的python代码:

3、之后我们会看到一下的结果

4、实际上,如果我们在浏览器上打开网页主页的话,右键选择“查看源代码”,你会发现,跟我们刚打印出来的是一模一样的。也就是说,上面的4行代码就已经帮我们把百度的首页和全部代码爬了下来了 。
5、下面我们介绍一下这四行代码,第一行如下图,这个就是将urllib2组件进入进来,供给我们使用。

6、图片下面这步骤是调用urllib2库中的urlopen方法,该方法接受一个url地址,然后将请求后的得到的回应封装到一个叫respones对象当中。

7、最后这里,是调用response对象的read()方法,将请求的回应内容以字符串的形式给html变量。最后的print html就是将字符串打出来,所以说一个基本的url请求是对应的python代码是很简单的。

总结:以上就是关于利用python爬虫获取百度信息的步骤内容,感谢大家的学习和对【听图阁-专注于Python设计】的支持。