yipeiwu_com6年前
关于爬虫乱码有很多各式各样的问题,这里不仅是中文乱码,编码转换、还包括一些如日文、韩文 、俄文、藏文之类的乱码处理,因为解决方式是一致的,故在此统一说明。 网络爬虫出现乱码的原因 源...
yipeiwu_com6年前
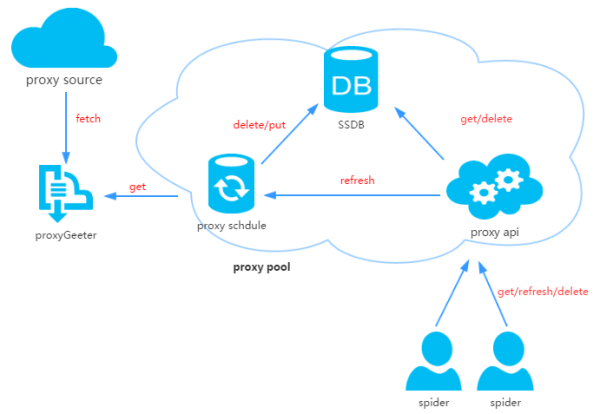
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东...
yipeiwu_com6年前
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。 举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式...
yipeiwu_com6年前
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论。但是,网易云音乐并没...
yipeiwu_com6年前
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容。它们的本质是一种递归的过程。它们首先需要获得网页的内容...
yipeiwu_com6年前
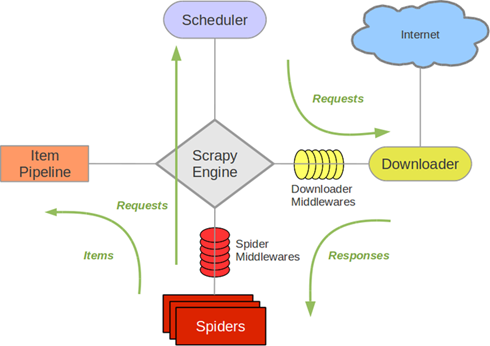
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了...
yipeiwu_com6年前
0x01 春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就...
yipeiwu_com6年前
前言 相信每位家长都有所体会,因为要在孩子出生后两周内起个名字(需要办理出生证明了),估计很多人都像我一样,刚开始是很慌乱的,虽然感觉汉字非常的多随便找个字做名字都行,后来才发现真不是随...
yipeiwu_com6年前
前言 可能很多人会觉得这是一个奇葩的需求,爬虫去好好的爬数据不就行了,解析js干嘛?吃饱了撑的? 搜索一下互联网上关于这个问题还真不少,但是大多数童鞋是因为自己的js基础太烂,要么是HT...
yipeiwu_com6年前
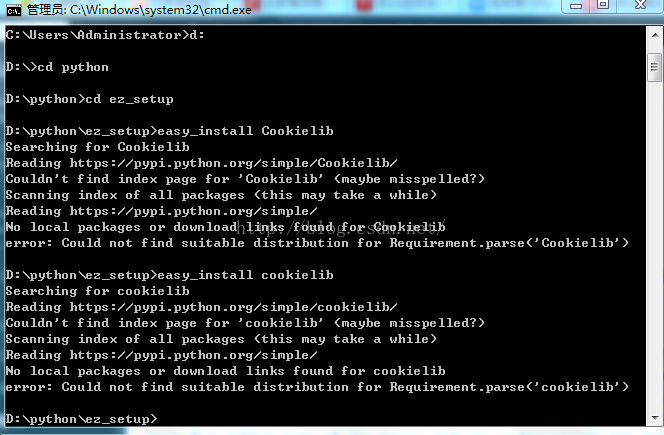
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一。搭建python(Windows版本) 1.安装python2.7 ---然后在cm...