Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载
scrapy框架
sublime text3
一。搭建python(Windows版本)
1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功

2.集成Scrapy框架----输入命令行:pip install Scrapy

安装成功界面如下:
失败的情况很多,举例一种:
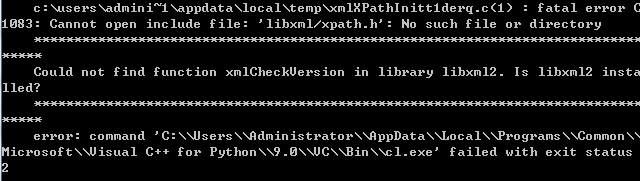
解决方案:
其余错误可百度搜索。
二。开始编程。
1.爬取无反爬虫措施的静态网站。例如百度贴吧,豆瓣读书。
例如-《桌面吧》的一个帖子https://tieba.baidu.com/p/2460150866?red_tag=3569129009
python代码如下:
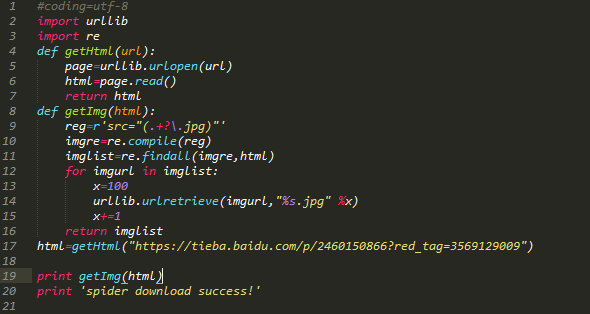
代码注释:引入了两个模块urllib,re。定义两个函数,第一个函数是获取整个目标网页数据,第二个函数是在目标网页中获取目标图片,遍历网页,并且给获取的图片按照0开始排序。
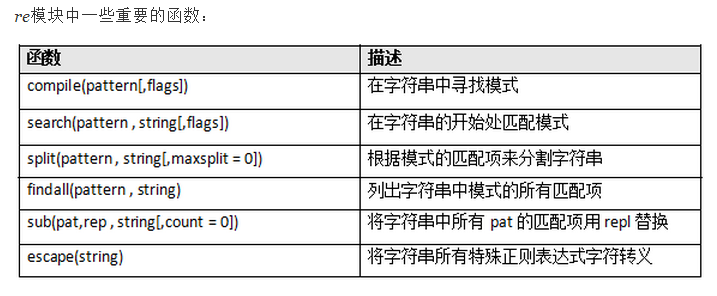
注:re模块知识点:
爬取图片效果图:
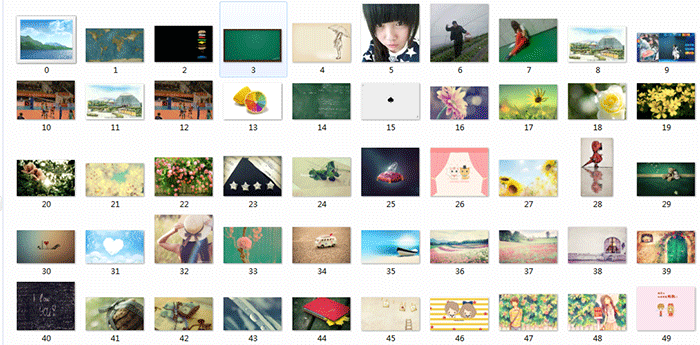
图片保存路径默认在建立的.py同目录文件下。
2.爬取有反爬虫措施的百度图片。如百度图片等。
例如关键字搜索“表情包”https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps=111111
图片采用滚动式加载,先爬取最优先的30张。
代码如下:
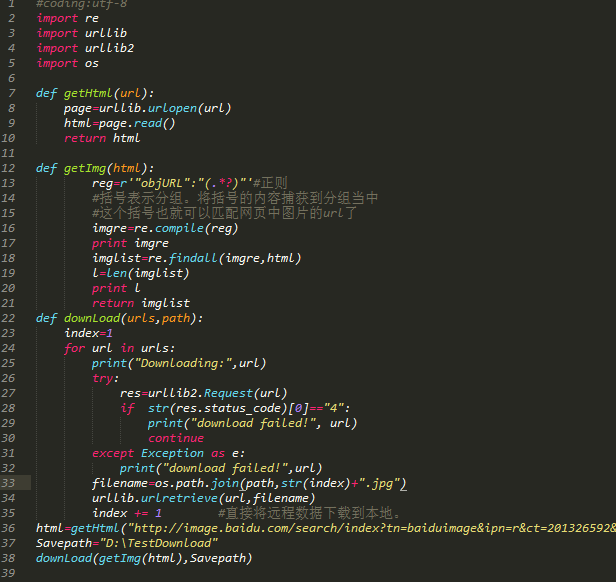
代码注释:导入4个模块,os模块用于指定保存路径。前两个函数同上。第三个函数使用了if语句,并tryException异常。
爬取过程如下:
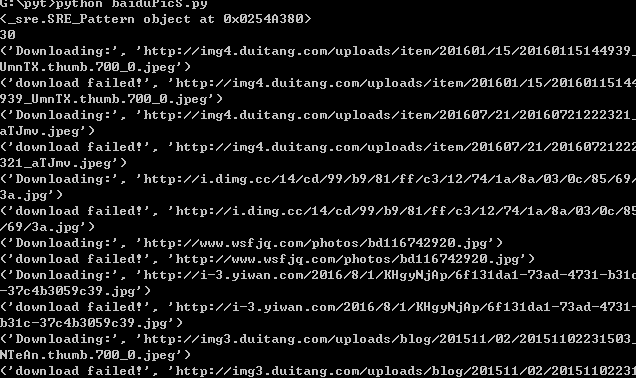
爬取结果:

注:编写python代码注重对齐,and不能混用Tab和空格,易报错。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持【听图阁-专注于Python设计】!