Python爬取网易云音乐上评论火爆的歌曲
前言
网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论。但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲。
结果
对过程没有兴趣的童鞋直接看这里啦。
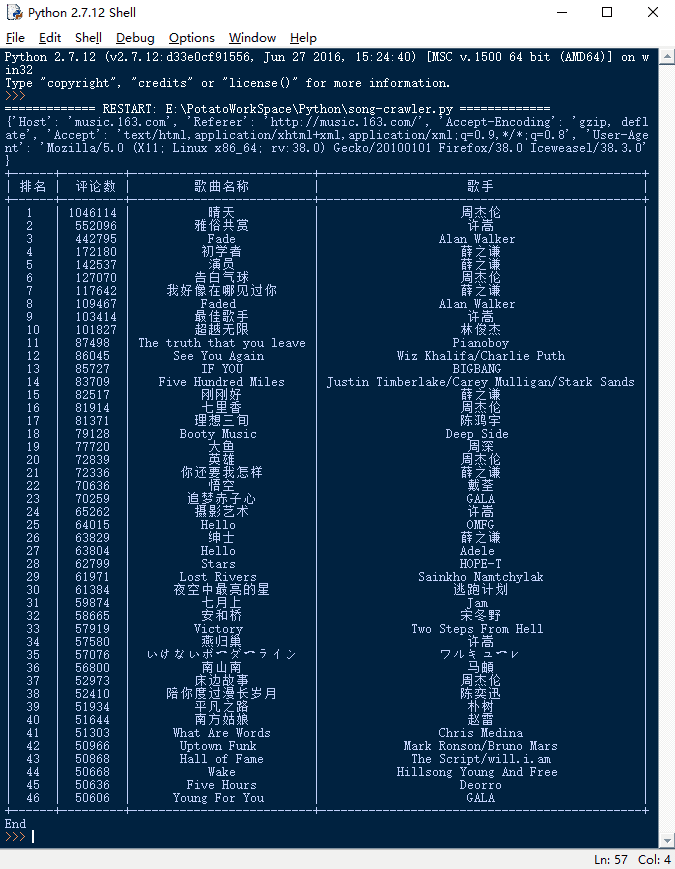
评论数大于五万的歌曲排行榜
首先恭喜一下我最喜欢的歌手(之一)周杰伦的《晴天》成为网易云音乐第一首评论数过百万的歌曲!
通过结果发现目前评论数过十万的歌曲正好十首,通过这前十首发现:
- 薛之谦现在真的很火啦~
- 几乎都是男歌手啊,男歌手貌似更受欢迎?(别打我),男歌手中周杰伦、薛之谦、许嵩(这三位我都比较喜欢)几乎占了榜单半壁江山...
- 《Fade》电音强势来袭,很带感哈(搭配炫迈写代码完全停不下来..)
根据结果做了网易云音乐歌单 :
提示: 评论数过五万的歌曲 歌单中个别歌曲由于版权问题暂时下架,暂由其他优秀版本代替。
高能预警:TOP 29 《Lost Rivers》请慎重播放,如果你坚持播放请先看评论...
过程
1、观察网易云音乐官网页面HTML结构
首页(http://music.163.com/)
歌单分类页(http://music.163.com/discover/playlist)。
歌单页(http://music.163.com/playlist?id=499518394)
歌曲详情页(http://music.163.com/song?id=109998)
2、爬取歌曲的ID
通过观察歌曲详情页的URL,我们发现只要爬取到对应歌曲的ID就可以得到它的详情页URL,而歌曲的信息都在详情页。由此可知只要收集到所有歌曲的ID那么就可以得到所有歌曲的信息啦。而这些ID要从哪里爬呢?从歌单里爬,而歌单在哪爬呢?通过观察歌单页的URL我们发现歌单也有ID,而歌单ID可以从歌单分类页中爬,好了就这样爬最终就能收集到所有歌曲的ID了。
3、通过爬取评论数筛选出符合条件的歌曲

很遗憾的是评论数虽然也在详情页内,但是网易云音乐做了防爬处理,采用AJAX调用评论数API的方式填充评论相关数据,由于异步的特性导致我们爬到的页面中评论数是空,那么我们就找一找这个API吧,通关观察XHR请求发现是下面这个家伙..


响应结果很丰富呢,所有评论相关的数据都有,不过经过观察发现这个API是经过加密处理的,不过没关系...
4、爬取符合条件的歌曲的详细信息(名字,歌手等)
这一步就很简单了,观察下歌曲详情页的HTML很容易就能爬到我们要的名字和歌手信息。
源码
# encoding=utf8
import requests
from bs4 import BeautifulSoup
import os, json
import base64
from Crypto.Cipher import AES
from prettytable import PrettyTable
import warnings
warnings.filterwarnings("ignore")
BASE_URL = 'http://music.163.com/'
_session = requests.session()
# 要匹配大于多少评论数的歌曲
COMMENT_COUNT_LET = 100000
class Song(object):
def __lt__(self, other):
return self.commentCount > other.commentCount
# 由于网易云音乐歌曲评论采取AJAX填充的方式所以在HTML上爬不到,需要调用评论API,而API进行了加密处理,下面是相关解决的方法
def aesEncrypt(text, secKey):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(secKey, 2, '0102030405060708')
ciphertext = encryptor.encrypt(text)
ciphertext = base64.b64encode(ciphertext)
return ciphertext
def rsaEncrypt(text, pubKey, modulus):
text = text[::-1]
rs = int(text.encode('hex'), 16) ** int(pubKey, 16) % int(modulus, 16)
return format(rs, 'x').zfill(256)
def createSecretKey(size):
return (''.join(map(lambda xx: (hex(ord(xx))[2:]), os.urandom(size))))[0:16]
# 通过第三方渠道获取网云音乐的所有歌曲ID
# 这里偷了个懒直接从http://grri94kmi4.app.tianmaying.com/songs爬了,这哥们已经把官网的歌曲都爬过来了,省事不少
# 也可以使用getSongIdList()从官方网站爬,相对比较耗时,但更准确
def getSongIdListBy3Party():
pageMax = 1 # 要爬的页数,可以根据需求选择性设置页数
songIdList = []
for page in range(pageMax):
url = 'http://grri94kmi4.app.tianmaying.com/songs?page=' + str(page)
# print url
url.decode('utf-8')
soup = BeautifulSoup(_session.get(url).content)
# print soup
aList = soup.findAll('a', attrs={'target': '_blank'})
for a in aList:
songId = a['href'].split('=')[1]
songIdList.append(songId)
return songIdList
# 从官网的 发现-> 歌单 页面爬取网云音乐的所有歌曲ID
def getSongIdList():
pageMax = 1 # 要爬的页数,目前一共42页,爬完42页需要很久很久,可以根据需求选择性设置页数
songIdList = []
for i in range(1, pageMax + 1):
url = 'http://music.163.com/discover/playlist/?order=hot&cat=全部&limit=35&offset=' + str(i * 35)
url.decode('utf-8')
soup = BeautifulSoup(_session.get(url).content)
aList = soup.findAll('a', attrs={'class': 'tit f-thide s-fc0'})
for a in aList:
uri = a['href']
playListUrl = BASE_URL + uri[1:]
soup = BeautifulSoup(_session.get(playListUrl).content)
ul = soup.find('ul', attrs={'class': 'f-hide'})
for li in ul.findAll('li'):
songId = (li.find('a'))['href'].split('=')[1]
print '爬取歌曲ID成功 -> ' + songId
songIdList.append(songId)
# 歌单里难免有重复的歌曲,去一下重复的歌曲ID
songIdList = list(set(songIdList))
return songIdList
# 匹配歌曲的评论数是否符合要求
# let 评论数大于值
def matchSong(songId, let):
url = BASE_URL + 'weapi/v1/resource/comments/R_SO_4_' + str(songId) + '/?csrf_token='
headers = {'Cookie': 'appver=1.5.0.75771;', 'Referer': 'http://music.163.com/'}
text = {'username': '', 'password': '', 'rememberLogin': 'true'}
modulus = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
nonce = '0CoJUm6Qyw8W8jud'
pubKey = '010001'
text = json.dumps(text)
secKey = createSecretKey(16)
encText = aesEncrypt(aesEncrypt(text, nonce), secKey)
encSecKey = rsaEncrypt(secKey, pubKey, modulus)
data = {'params': encText, 'encSecKey': encSecKey}
req = requests.post(url, headers=headers, data=data)
total = req.json()['total']
if int(total) > let:
song = Song()
song.id = songId
song.commentCount = total
return song
# 设置歌曲的信息
def setSongInfo(song):
url = BASE_URL + 'song?id=' + str(song.id)
url.decode('utf-8')
soup = BeautifulSoup(_session.get(url).content)
strArr = soup.title.string.split(' - ')
song.singer = strArr[1]
name = strArr[0].encode('utf-8')
# 去除歌曲名称后面()内的字,如果不想去除可以注掉下面三行代码
index = name.find('(')
if index > 0:
name = name[0:index]
song.name = name
# 获取符合条件的歌曲列表
def getSongList():
print ' ##正在爬取歌曲编号... ##'
# songIdList = getSongIdList()
songIdList = getSongIdListBy3Party()
print ' ##爬取歌曲编号完成,共计爬取到' + str(len(songIdList)) + '首##'
songList = []
print ' ##正在爬取符合评论数大于' + str(COMMENT_COUNT_LET) + '的歌曲... ##'
for id in songIdList:
song = matchSong(id, COMMENT_COUNT_LET)
if None != song:
setSongInfo(song)
songList.append(song)
print '成功匹配一首{名称:', song.name, '-', song.singer, ',评论数:', song.commentCount, '}'
print ' ##爬取完成,符合条件的的共计' + str(len(songList)) + '首##'
return songList
def main():
songList = getSongList()
# 按评论数从高往低排序
songList.sort()
# 打印结果
table = PrettyTable([u'排名', u'评论数', u'歌曲名称', u'歌手'])
for index, song in enumerate(songList):
table.add_row([index + 1, song.commentCount, song.name, song.singer])
print table
print 'End'
if __name__ == '__main__':
main()
友情提示:随着网易云音乐网站结构、接口、加密方式的更换本代码可能并不能很好的工作,不过过程和原理都是一样的,这里也只是给大家分享一下这一过程啦。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。