Python爬虫实例扒取2345天气预报
寒假里学习了一下Python爬虫,使用最简单的方法扒取需要的天气数据,对,没听错,最简单的方法。甚至没有一个函数封装。。
网址:http://tianqi.2345.com/wea_history/53892.htm
火狐中右键查看网页源代码,没有发现天气数据,因此推断网页采用的json格式数据。
右击->查看元素->网络->JS,找到了位置
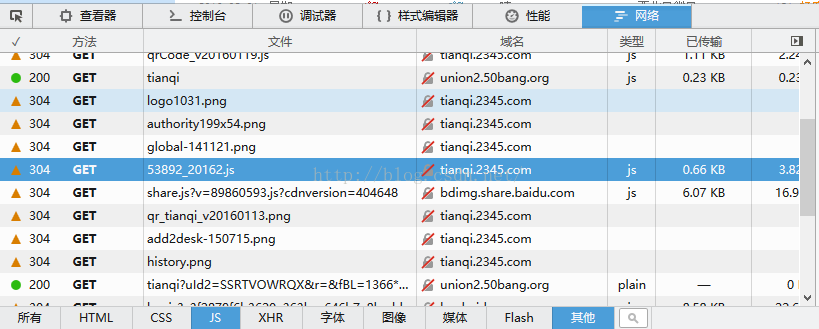
用Python爬虫下载为json格式数据存储下来,代码如下:
#-*- coding:utf-8 -*-
import urllib2
import json
months = [1,2,3,4,5,6,7,8,9,10,11,12]
years = [2011,2012,2013,2014,2015,2016]
city = [53892] #邯郸代码53892
for y in years:
for m in months:
for c in city:
url = "http://tianqi.2345.com/t/wea_history/js/"+str(c)+"_"+str(y)+str(m)+".js?qq-pf-to=pcqq.c2c"
print url
html = urllib2.urlopen(url)
srcData = html.read()
#JsonData = json.loads(srcData)
file = open("d:/json/"+str(c)+"handan/weather"+str(c)+"_"+str(y)+str(m)+".json","w")
file.write(srcData)
file.close()
扒取存到本地:因为是刚学,学一点就动手实践了一下,还没有学到json的转换,直接使用的正则匹配,提取json中的数据,直接打印
提取转换json文件中的数据Python代码:
#-*- coding:utf-8 -*-
import json
import re
import time
Year = [2014]
Month = [1]
for y in Year:
for m in Month:
"""
2016年2月15日终于改成功。
是因为正则匹配后的编码问题,导致输出时无法显示。
在每个正则匹配的元组后添加 .decode('gbk').encode('utf-8'),成功输出
"""
content = fRead.read()
pattern = re.compile('{ymd:\'(.*?)\',bWendu:\'(.*?)\',yWendu:\'(.*?)\',tianqi:\'(.*?)\',fengxiang:\'(.*?)\',fengli:\'(.*?)\'},',re.S)
items = re.findall(pattern,content)
for item in items:
print item[0].decode('gbk').encode('utf-8'),","+item[1].decode('gbk').encode('utf-8'),","+item[2].decode('gbk').encode('utf-8'),","+item[3].decode('gbk').encode('utf-8'),","+item[4].decode('gbk').encode('utf-8'),","+item[5].decode('gbk').encode('utf-8')
time.sleep(0.1)
fRead.close()
使用Sublime Text 3运行
使用正则处理的一大问题就是,格式不整齐,总会漏掉一些数据。可能是由于匹配的速度过快导致部分数据缺失,但是通过time.sleep() 睡眠依旧不能解决问题。
由此可以看出正则匹配时的缺陷,待以后使用Python中专门用于处理json数据的包以后,再重新试一下