yipeiwu_com6年前
做爬虫项目时,我们需要考虑一个爬虫在爬取时会遇到各种情况(网站验证,ip封禁),导致爬虫程序中断,这时我们已经爬取过一些数据,再次爬取时这些数据就可以忽略,所以我们需要在爬虫项目中设置一...
yipeiwu_com6年前
代码如下 from fake_useragent import UserAgent from lxml import etree import requests, os import...
yipeiwu_com6年前
模块安装 参考官方文档安装 pip install PyExecJS 配置 该模块需要JS运行时环境 以下JS runtime经过官方测试认可,建议采用 PyV8:一...
yipeiwu_com6年前
本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1、任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识...
yipeiwu_com6年前
本次博客分享的内容为基于有道在线翻译实现一个实时翻译小程序,本次任务是参考小甲鱼的书《零基础入门学习Python》完成的,书中代码对于当前的有道词典并不适用,使用后无法实现翻译功能,在网...
yipeiwu_com6年前
两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 import requests from lxm...
yipeiwu_com6年前
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 sess...
yipeiwu_com6年前
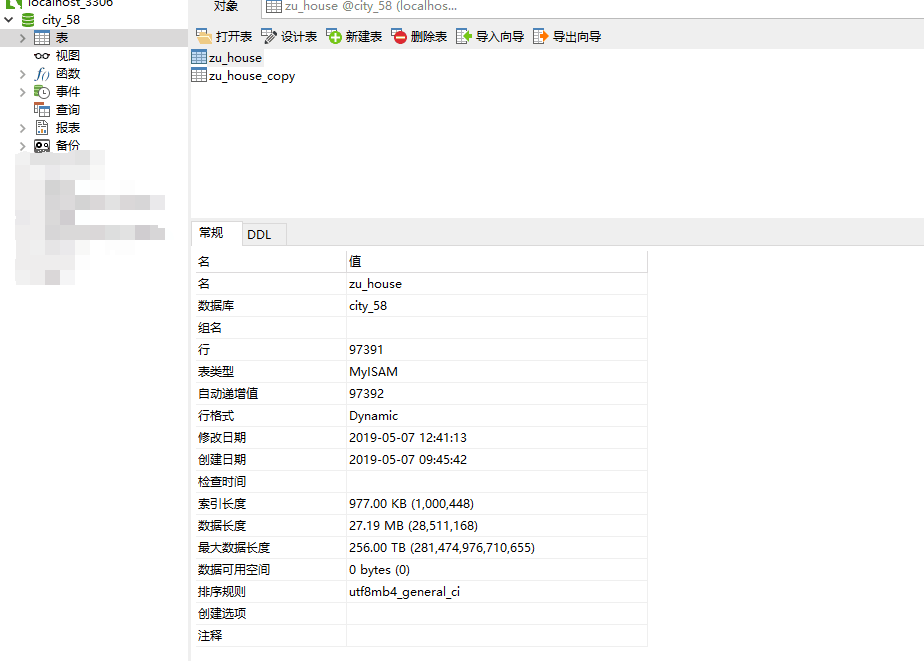
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com...
yipeiwu_com6年前
如果直接从生成验证码的页面把验证码下载到本地后识别,再构造表单数据发送的话,会有一个验证码同步的问题,即请求了两次验证码,而识别出来的验证码并不是实际需要发送的验证码。有如下几种方法解决...
yipeiwu_com6年前
窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案。 到上面去看了看,地址都是明文的,得,赶紧开始吧。 下载流式文件,re...