yipeiwu_com6年前
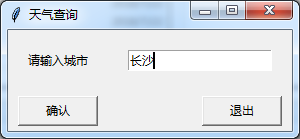
执行效果如下: from tkinter import * import urllib.request import gzip import json from tkinter...
yipeiwu_com6年前
本文实例讲述了python实现爬取百度图片的方法。分享给大家供大家参考,具体如下: import json import itertools import urllib import...
yipeiwu_com6年前
本文实例讲述了Python 实现的微信爬虫。分享给大家供大家参考,具体如下: 单线程版: import urllib.request import urllib.parse impo...
yipeiwu_com6年前
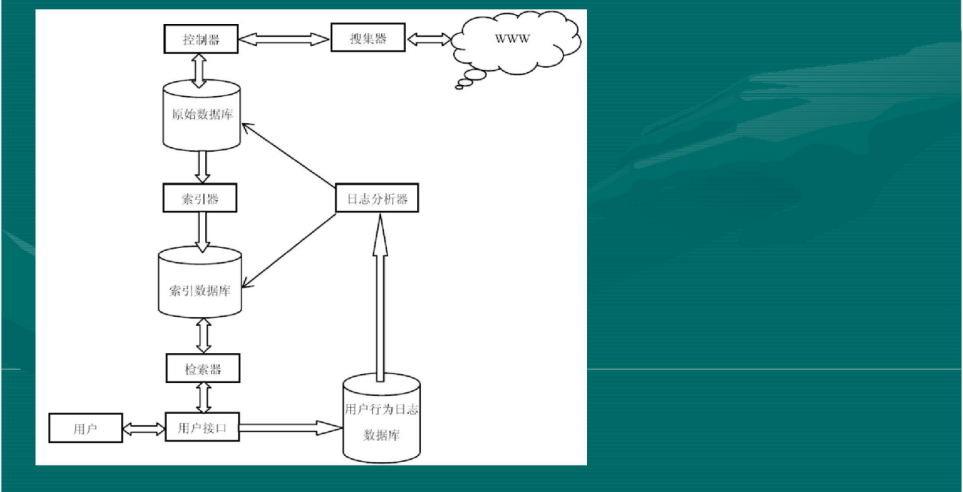
什么是网络爬虫? 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过...
yipeiwu_com6年前
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下怎么用IP代理防止被封 首先,设置等待时间: 常见的设置等待时间有两种,一种是...
yipeiwu_com6年前
前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示、直方图展示、词云展示等...
yipeiwu_com6年前
今天为大家整理了32个Python爬虫项目。 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心。所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatS...
yipeiwu_com6年前
python3.7简单的爬虫,具体代码如下所示: #https://www.runoob.com/w3cnote/python-spider-intro.html #Python...
yipeiwu_com6年前
前言 一般js破解有两种方法,一种是用Python重写js逻辑,一种是利用第三方库来调用js内容获取结果。这两种方法各有利弊,第一种方法性能好,但对js和Python要求掌握比较高;第二...
yipeiwu_com6年前
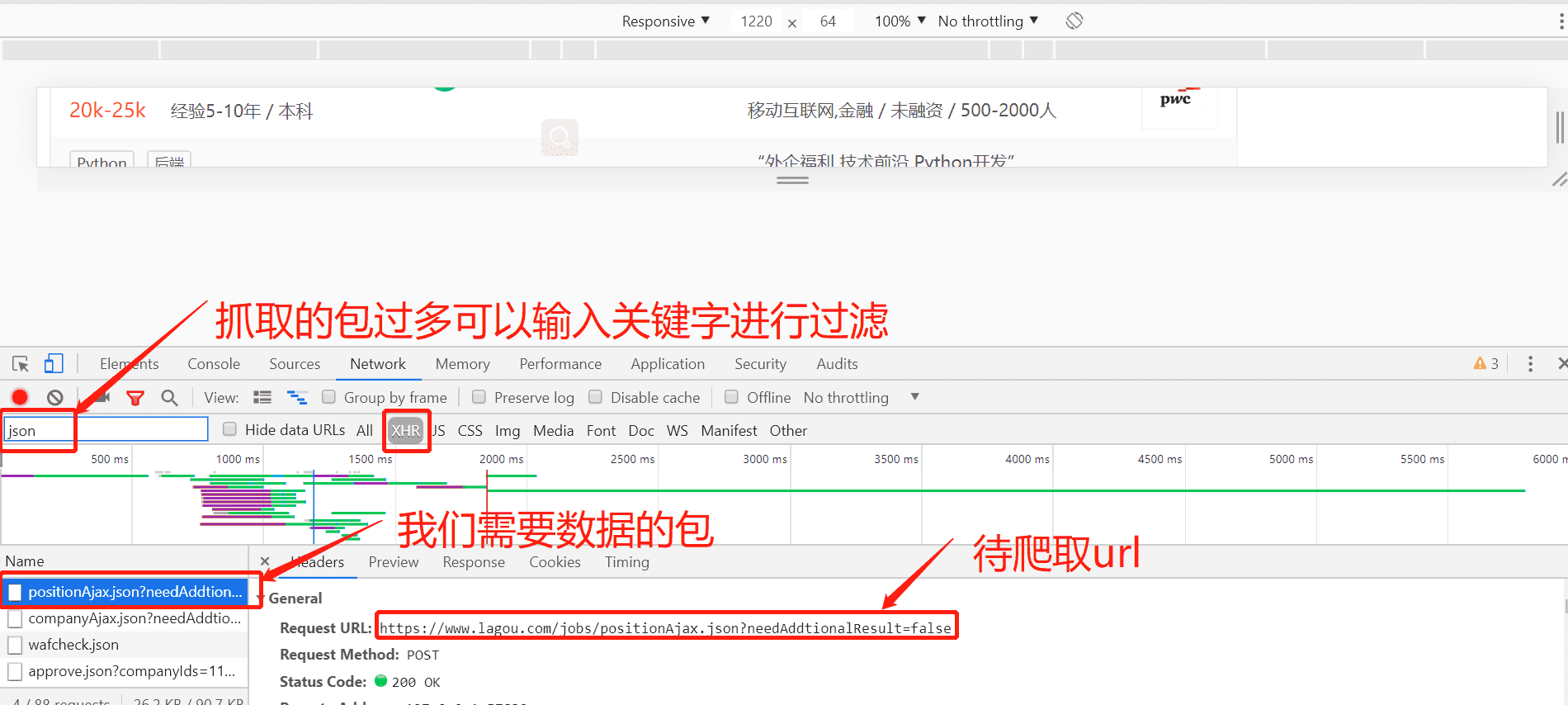
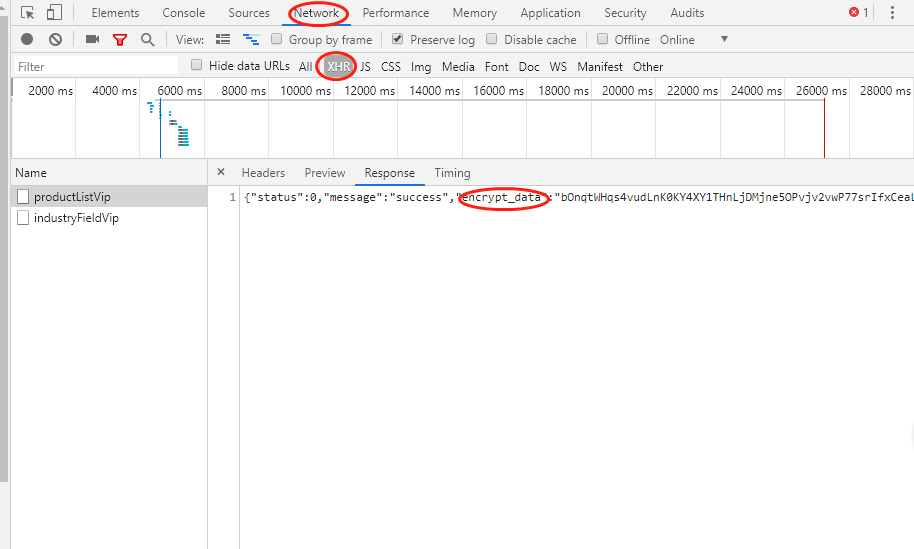
前言 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了。 我把js反爬分为参数由js加密生成和js生成cookie等来操作浏览器...