Python爬虫动态ip代理防止被封的方法
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下怎么用IP代理防止被封
首先,设置等待时间:
常见的设置等待时间有两种,一种是显性等待时间(强制停几秒),一种是隐性等待时间(看具体情况,比如根据元素加载完成需要时间而等待)图1是显性等待时间设置,图2是隐性


第二步,修改请求头:
识别你是机器人还是人类浏览器浏览的重要依据就是User-Agent,比如人类用浏览器浏览就会使这个样子的User-Agent:'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'

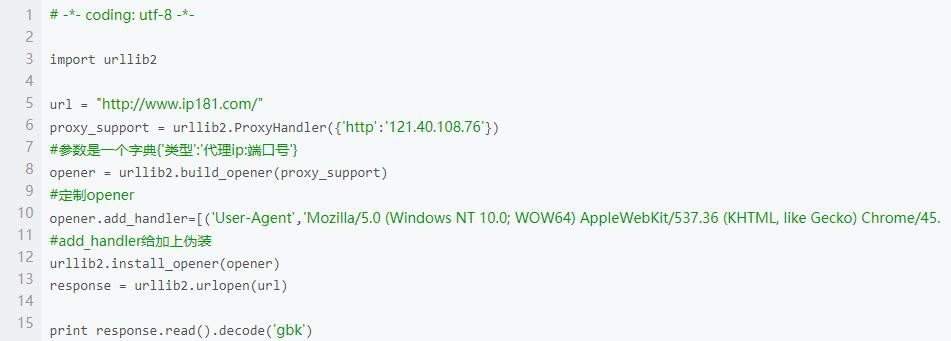
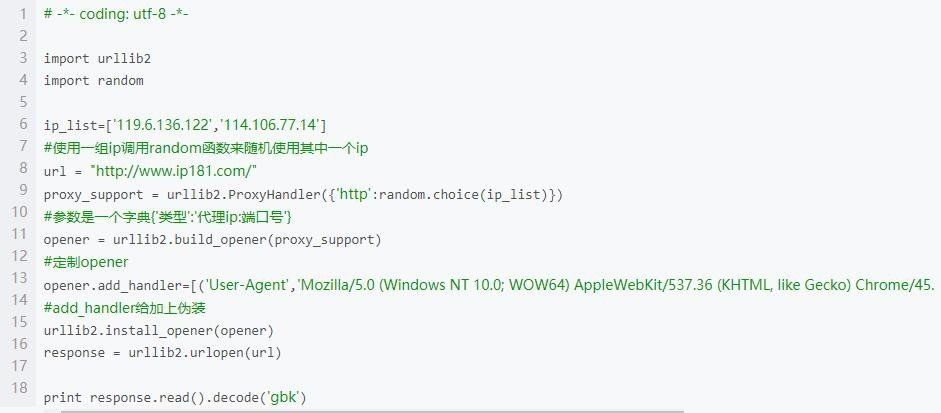
第三步,采用代理ip/建代理ip池
直接看代码。利用动态ip代理,可以强有力地保障爬虫不会被封,能够正常运行。图1为使用代理ip的情况,图2是建ip代理池的代码,有没有必要需要看自己的需求,大型项目是必须用大量ip的。
做好以上3个步骤,大致爬虫的运行就不成问题了。做好以上3个步骤,大致爬虫的运行就不成问题了。
以上就是本次介绍的全部内容,感谢大家的学习和对【听图阁-专注于Python设计】的支持。