yipeiwu_com6年前
是否了解线程的同步和异步? 线程同步:多个线程同时访问同一资源,等待资源访问结束,浪费时间,效率低 线程异步:在访问资源时在空闲等待时同时访问其他资源,实现多线程机制 是否...
yipeiwu_com6年前
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间。 一、创建Scrapy项目 scrapy startproject Ten...
yipeiwu_com6年前
大家可以在Github上clone全部源码。 Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:ht...
yipeiwu_com6年前
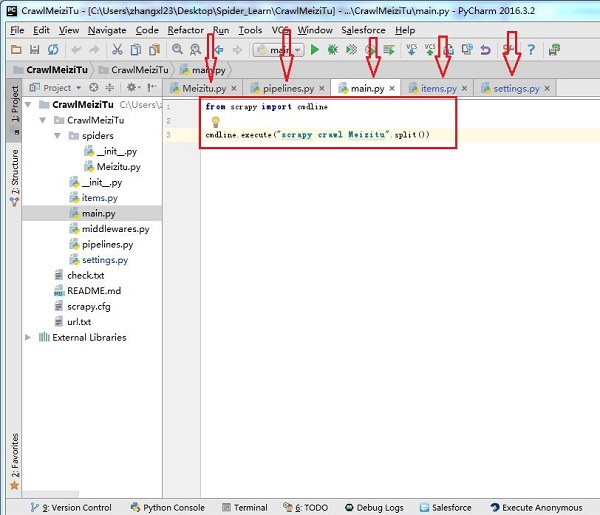
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行。 最简单的方法:直接...
yipeiwu_com6年前
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度、高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲...
yipeiwu_com6年前
寒假里学习了一下Python爬虫,使用最简单的方法扒取需要的天气数据,对,没听错,最简单的方法。甚至没有一个函数封装。。 网址:http://tianqi.2345.com/wea_hi...
yipeiwu_com6年前
爬虫简介 根据百度百科定义:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照...
yipeiwu_com6年前
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv i...
yipeiwu_com6年前
python书籍信息爬虫示例,供大家参考,具体内容如下 背景说明 需要收集一些书籍信息,以豆瓣书籍条目作为源,得到一些有效书籍信息,并保存到本地数据库。 获取书籍分类标签 具体可参考这个...
yipeiwu_com6年前
注:答案一般在网上都能够找到。 1.对if __name__ == 'main'的理解陈述 2.python是如何进行内存管理的? 3.请写出一段Python代码实现删除一个lis...