Python爬虫设置代理IP的方法(爬虫技巧)
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度、高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP。
(一)配置环境
- 安装requests库
- 安装bs4库
- 安装lxml库
(二)代码展示
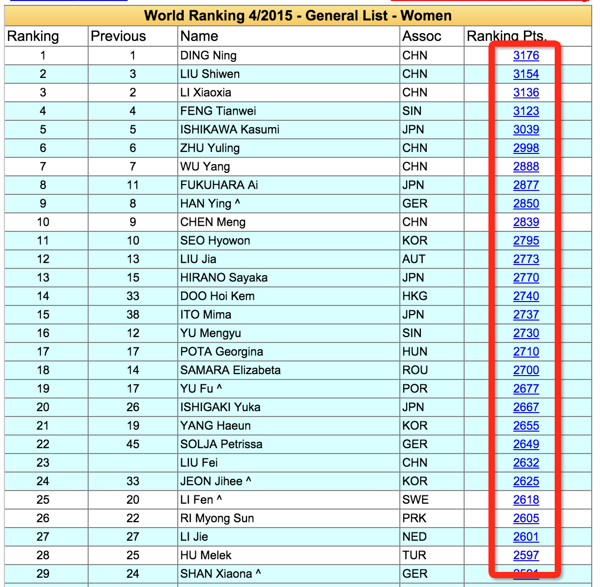
# IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
if __name__ == '__main__':
url = 'http://www.xicidaili.com/nn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
ip_list = get_ip_list(url, headers=headers)
proxies = get_random_ip(ip_list)
print(proxies)函数get_ip_list(url, headers)传入url和headers,最后返回一个IP列表,列表的元素类似42.84.226.65:8888格式,这个列表包括国内髙匿代理IP网站首页所有IP地址和端口。
函数get_random_ip(ip_list)传入第一个函数得到的列表,返回一个随机的proxies,这个proxies可以传入到requests的get方法中,这样就可以做到每次运行都使用不同的IP访问被爬取的网站,有效地避免了真实IP被封的风险。proxies的格式是一个字典:{‘http': ‘http://42.84.226.65:8888‘}。
(三)代理IP的使用
运行上面的代码会得到一个随机的proxies,把它直接传入requests的get方法中即可。
web_data = requests.get(url, headers=headers, proxies=proxies)
总结
以上所述是小编给大家介绍的Python爬虫设置代理IP的方法(爬虫技巧),希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!