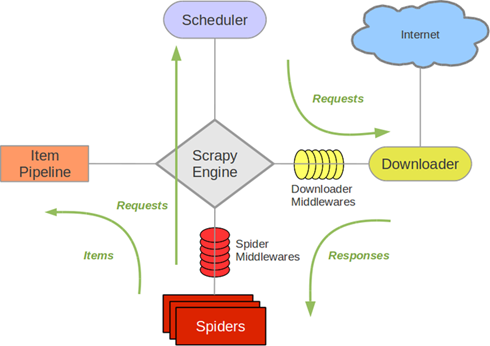
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行。
最简单的方法:直接使用Timer类
import time
import os
while True:
os.system("scrapy crawl News")
time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块
import sched
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
schedule = sched.scheduler ( time.time, time.sleep )
#被周期性调度触发的函数
def func():
os.system("scrapy crawl News")
def perform1(inc):
schedule.enter(inc,0,perform1,(inc,))
func() # 需要周期执行的函数
def mymain():
schedule.enter(0,0,perform1,(86400,))
if __name__=="__main__":
mymain()
schedule.run() # 开始运行,直到计划时间队列变成空为止关于cmd的实现方法,本人在单次执行爬虫程序时使用的是
cmdline.execute("scrapy crawl News".split())但可能因为cmdline是scrapy模块中自带的,所以定时执行时只能执行一次就退出了。
小伙伴有种方法是使用
import subprocess
subprocess.Popen("scrapy crawl News")
她的程序运行正常可以定时多次执行,而我的却直接退出了,改为
from subprocess import Popen
subprocess.Popen("scrapy crawl News")
才正常,不知道为什么会这样,如果有大神可以解释原因还请指点。
反正
os.system、subprocess.Popen
都是pythoncmd的实现方法,可以根据需要选择使用。
总结
以上所述是小编给大家介绍的python实现scrapy定时执行爬虫,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!