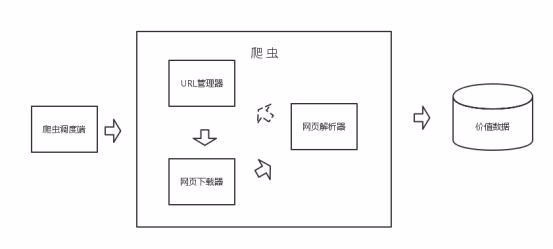
浅析Python3爬虫登录模拟
使用Python爬虫登录系统之后,能够实现的操作就多了很多,下面大致介绍下如何使用Python模拟登录。
我们都知道,在前端的加密验证,只要把将加密环境还原出来,便能够很轻易地登录。
首先分析登录的步骤,通过审查元素得知
<input type="button" id="login" name="login" class="login" onclick="Logon();" value="登录">
点击按钮触发Logon()函数,然后查找Logon()函数定义
function Logon() {
}
函数定义内容各有不同,一般里面包含一些加密的操作,一般是使用写好的js加密。我们所需要做的便是重复这些步骤,加密数据。
对于加密,有三种方法:
- 如果加密方法是base64之类的,可以直接用Python3的base64库加密;
- 手动模仿;
- 直接调用js加密,需要先下载PyExecJS,有的电脑需要先安装js的运行环境,比如Node.js。使用方法如下:
newusername = execjs.compile(content).call('base64encode', username)
其中content是js内容,base64encode是方法,username是参数,newusername是加密后的数据。
对于验证码的问题,先介绍下一般的图片验证码,可以请求获取验证码的地址,session之类的数据自己搞定,一般便可以请求成功,可以存到本地手动输入,也可以使用识别的第三方模块,但这个识别效果并不是很好。
然后,便是查看session,cookie。
接下来的操作就是构造请求头headers,这个可以自行去控制台查看或者使用wireshark, fiddler之类的抓包软件查看。
最后便可以请求数据:
使用
s = requests.Session() s.headers.update(headers) r = s.post(url, data = params)
或者:
r = requests.get(url, headers = headers, data = params)
headers是你构造的请求头,url是你请求的网站,params是加密的数据。