深入理解Python分布式爬虫原理
首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。
(1)打开浏览器,输入URL,打开源网页
(2)选取我们想要的内容,包括标题,作者,摘要,正文等信息
(3)存储到硬盘中
上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储。
我们使用Python写一个简单的程序,实现上面的简单抓取功能。
#!/usr/bin/python
#-*- coding: utf-8 -*-
'''''
Created on 2014-03-16
@author: Kris
'''
import urllib2, re, cookielib
def httpCrawler(url):
'''''
@summary: 网页抓取
'''
content = httpRequest(url)
title = parseHtml(content)
saveData(title)
def httpRequest(url):
'''''
@summary: 网络请求
'''
try:
ret = None
SockFile = None
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322)')
request.add_header('Pragma', 'no-cache')
opener = urllib2.build_opener()
SockFile = opener.open(request)
ret = SockFile.read()
finally:
if SockFile:
SockFile.close()
return ret
def parseHtml(html):
'''''
@summary: 抓取结构化数据
'''
content = None
pattern = '<title>([^<]*?)</title>'
temp = re.findall(pattern, html)
if temp:
content = temp[0]
return content
def saveData(data):
'''''
@summary: 数据存储
'''
f = open('test', 'wb')
f.write(data)
f.close()
if __name__ == '__main__':
url = 'http://www.baidu.com'
httpCrawler(url)
看着很简单,是的,它就是一个爬虫入门的基础程序。当然,在实现一个采集过程,无非就是上面的几个基础步骤。但是实现一个强大的采集过程,你会遇到下面的问题:
(1)需要带着cookie信息访问,比如大多数的社交化软件,基本上都是需要用户登录之后,才能看到有价值的东西,其实很简单,我们可以使用Python提供的cookielib模块,实现每次访问都带着源网站给的cookie信息去访问,这样只要我们成功模拟了登录,爬虫处于登录状态,那么我们就可以采集到登录用户看到的一切信息了。下面是使用cookie对httpRequest()方法的修改:
ckjar = cookielib.MozillaCookieJar()
cookies = urllib2.HTTPCookieProcessor(ckjar) #定义cookies对象
def httpRequest(url):
'''''
@summary: 网络请求
'''
try:
ret = None
SockFile = None
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322)')
request.add_header('Pragma', 'no-cache')
opener = urllib2.build_opener(cookies) #传递cookies对象
SockFile = opener.open(request)
ret = SockFile.read()
finally:
if SockFile:
SockFile.close()
return ret
(2)编码问题。网站目前最多的两种编码:utf-8,或者gbk,当我们采集回来源网站编码和我们数据库存储的编码不一致时,比如,163.com的编码使用的是gbk,而我们需要存储的是utf-8编码的数据,那么我们可以使用Python中提供的encode()和decode()方法进行转换,比如:
content = content.decode('gbk', 'ignore') #将gbk编码转为unicode编码
content = content.encode('utf-8', 'ignore') #将unicode编码转为utf-8编码
中间出现了unicode编码,我们需要转为中间编码unicode,才能向gbk或者utf-8转换。
(3)网页中标签不完整,比如有些源代码中出现了起始标签,但没有结束标签,HTML标签不完整,就会影响我们抓取结构化数据,我们可以通过Python的BeautifulSoup模块,先对源代码进行清洗,再分析获取内容。
(4)某些网站使用JS来生存网页内容。当我们直接查看源代码的时候,发现是一堆让人头疼的JS代码。可以使用mozilla、webkit等可以解析浏览器的工具包解析js、ajax,虽然速度会稍微慢点。
(5)图片是flash形式存在的。当图片中的内容是文字或者数字组成的字符,那这个就比较好办,我们只要利用ocr技术,就能实现自动识别了,但是如果是flash链接,我们将整个URL存储起来了。
(6)一个网页出现多个网页结构的情况,这样我们如果只是一套抓取规则,那肯定不行,所以需要配置多套模拟进行协助配合抓取。
(7)应对源网站的监控。抓取别人的东西,毕竟是不太好的事情,所以一般网站都会有针对爬虫禁止访问的限制。
一个好的采集系统,应该是,不管我们的目标数据在何处,只要是用户能够看到的,我们都能采集回来。所见即所得的无阻拦式采集,无论是否需要登录的数据都能够顺利采集。大部分有价值的信息,一般都需要登录才能看到,比如社交网站,为了应对登录的网站要有模拟用户登录的爬虫系统,才能正常获取数据。不过社会化网站都希望自己形成一个闭环,不愿意把数据放到站外,这种系统也不会像新闻等内容那么开放的让人获取。这些社会化网站大部分会采取一些限制防止机器人爬虫系统爬取数据,一般一个账号爬取不了多久就会被检测出来被禁止访问了。那是不是我们就不能爬取这些网站的数据呢?肯定不是这样的,只要社会化网站不关闭网页访问,正常人能够访问的数据,我们也能访问。说到底就是模拟人的正常行为操作,专业一点叫“反监控”。
源网站一般会有下面几种限制:
1、一定时间内单个IP访问次数,一个正常用户访问网站,除非是随意的点着玩,否则不会在一段持续时间内过快访问一个网站,持续时间也不会太长。这个问题好办,我们可以采用大量不规则代理IP形成一个代理池,随机从代理池中选择代理,模拟访问。代理IP有两种,透明代理和匿名代理。
2、一定时间内单个账号访问次数,如果一个人一天24小时都在访问一个数据接口,而且速度非常快,那就有可能是机器人了。我们可以采用大量行为正常的账号,行为正常就是普通人怎么在社交网站上操作,并且单位时间内,访问URL数目尽量减少,可以在每次访问中间间隔一段时间,这个时间间隔可以是一个随机值,即每次访问完一个URL,随机随眠一段时间,再接着访问下一个URL。
如果能把账号和IP的访问策略控制好了,基本就没什么问题了。当然对方网站也会有运维会调整策略,敌我双方的一场较量,爬虫必须要能感知到对方的反监控将会对我们有影响,通知管理员及时处理。其实最理想的是能够通过机器学习,智能的实现反监控对抗,实现不间断地抓取。
下面是本人近期正在设计的一个分布式爬虫架构图,如图1所示:
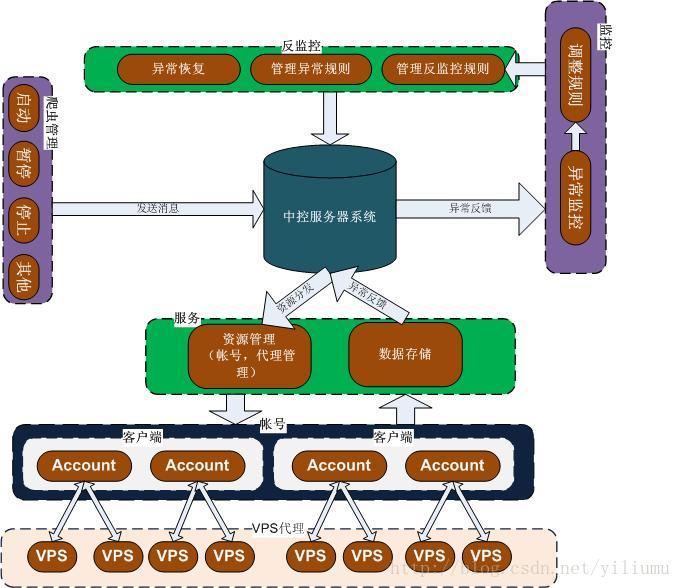
纯属拙作,初步思路正在实现,正在搭建服务器和客户端之间的通信,主要使用了Python的Socket模块实现服务器端和客户端的通信。如果有兴趣,可以单独和我联系,共同探讨完成更优的方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。