pycharm下打开、执行并调试scrapy爬虫程序的方法
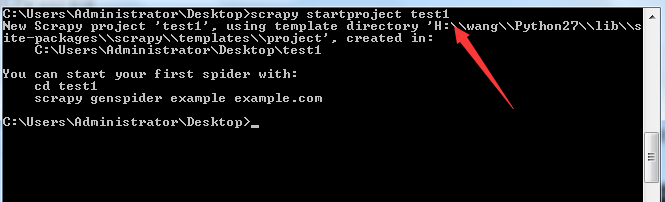
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1
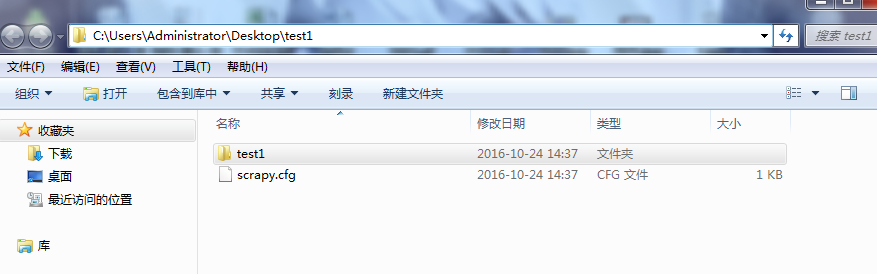
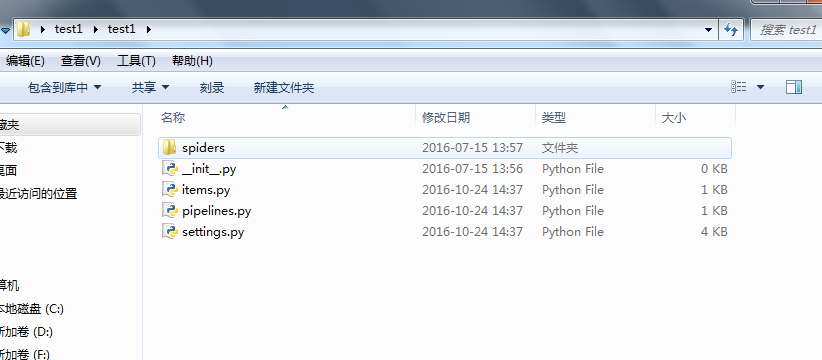
目录结构如下:
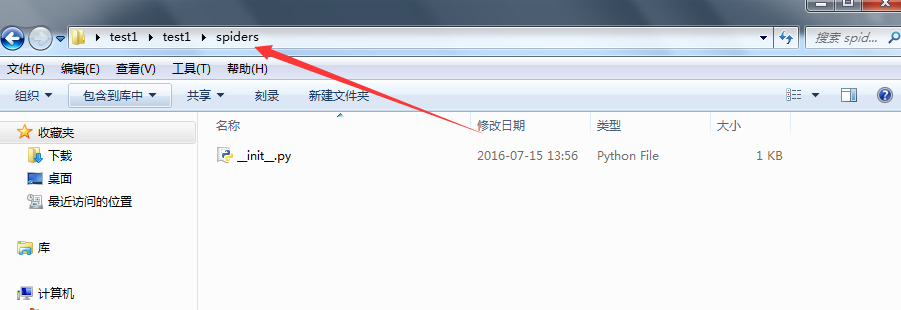
打开Pycharm,选择open

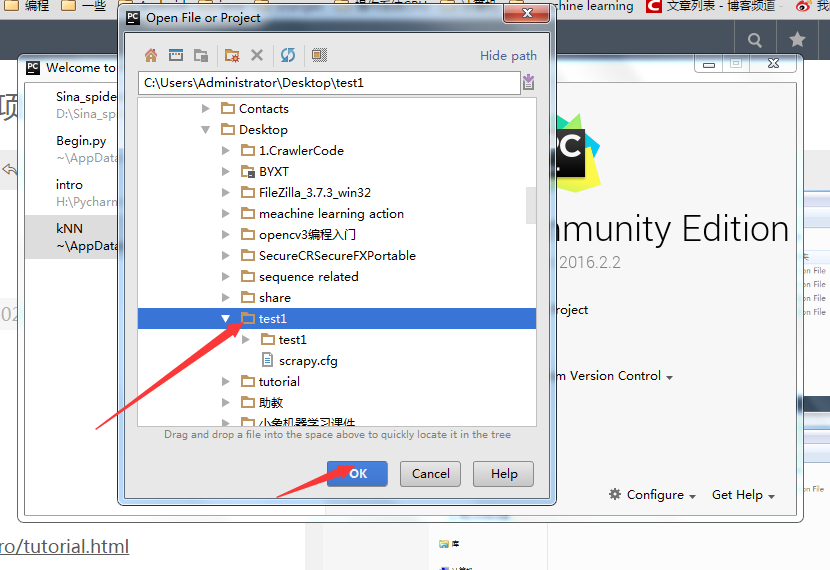
选择项目,ok
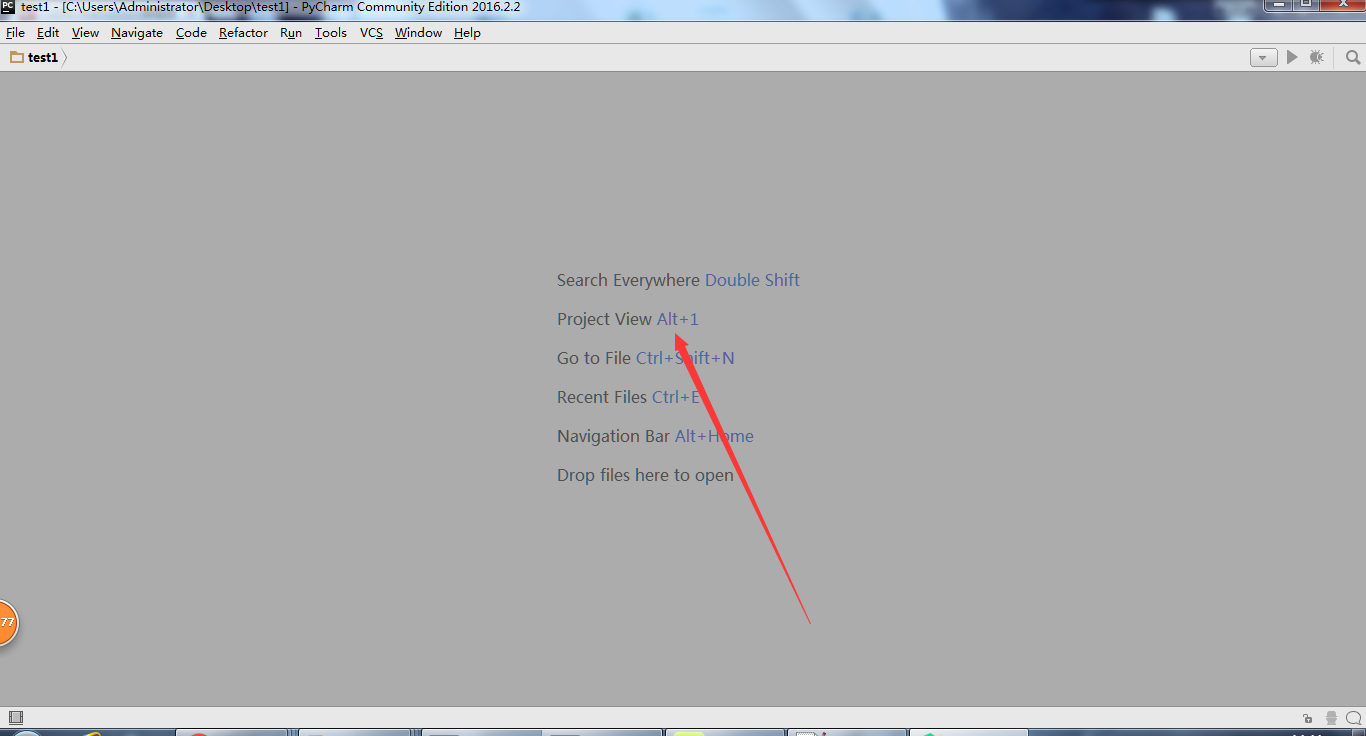
打开如下界面之后,按alt + 1, 打开project 面板
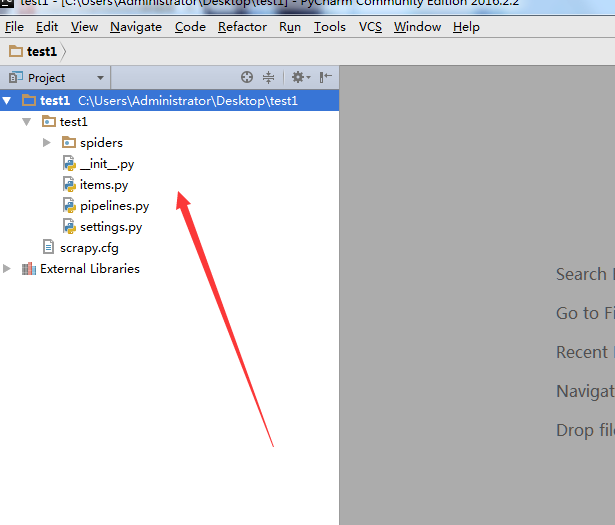
在test1/spiders/,文件夹下,新建一个爬虫spider.py, 注意代码中的name="dmoz"。这个名字后面会用到。
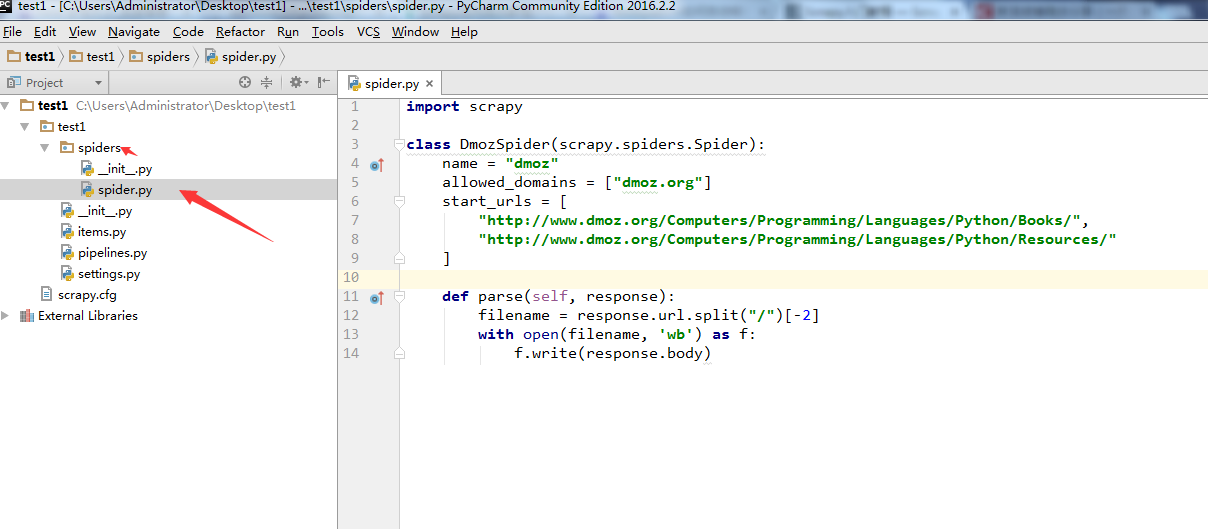
在test1目录和scrapy.cfg同级目录下面,新建一个begin.py文件(便于理解可以写成main.py),注意箭头2所指的名字和第5步中的name='dmoz'名字是一样的。
from scrapy import cmdline
cmdline.execute("scrapy crawl dmoz".split())
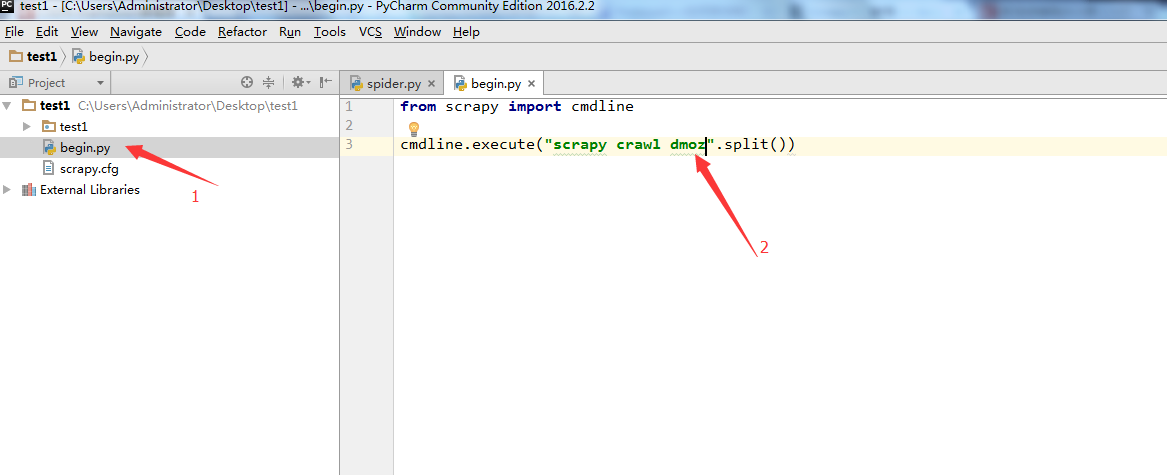
7. 上面把文件搞定了,下面要配置一下pycharm了。点击Run->Edit Configurations
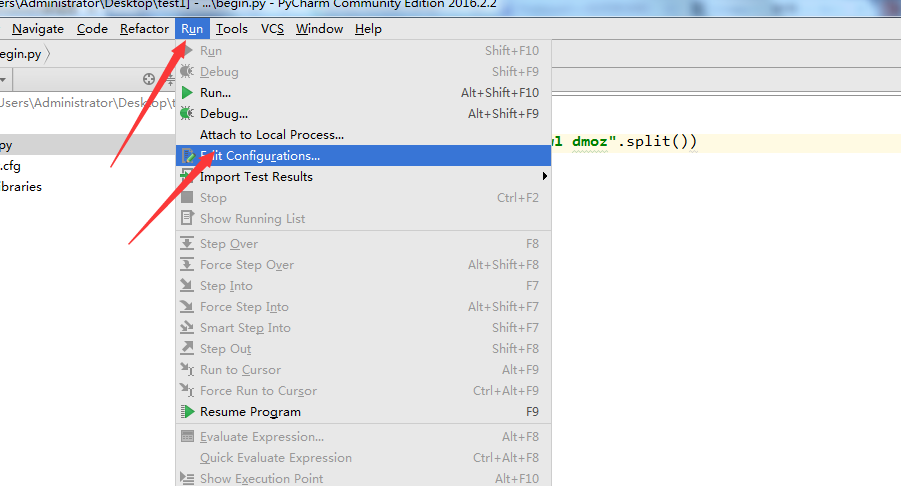
8. 新建一个运行的python模块

9. Name:改成spider; script:选择刚才新建的那个begin.py文件;Working Direciton:改成自己的工作目录
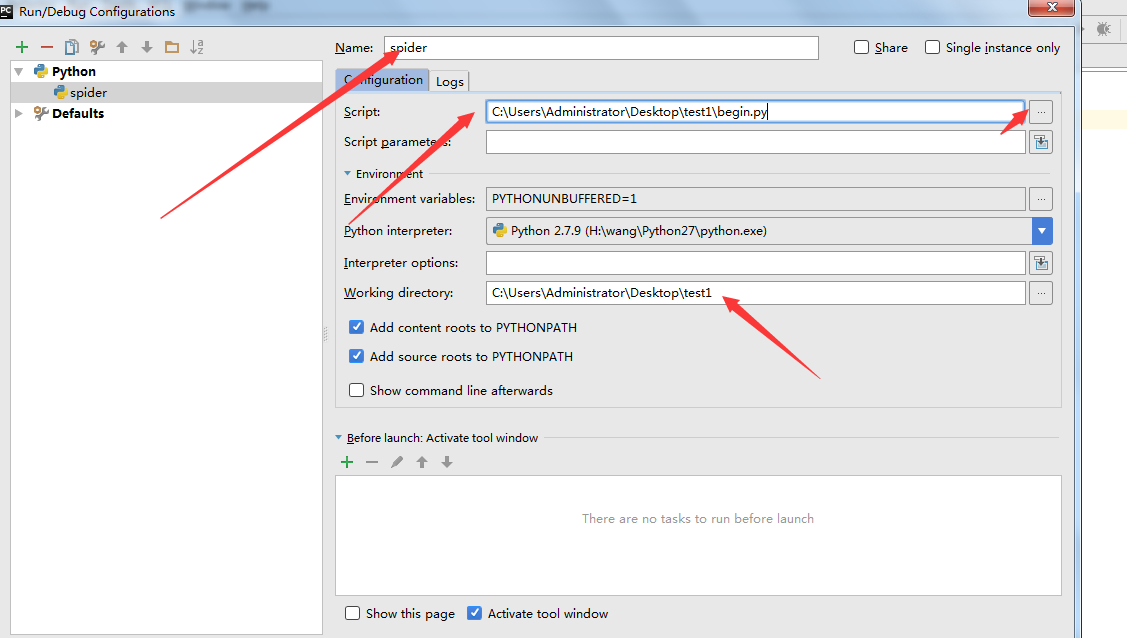
10. 至此,大功告成了,点击下图,右上角的按钮就能运行了。
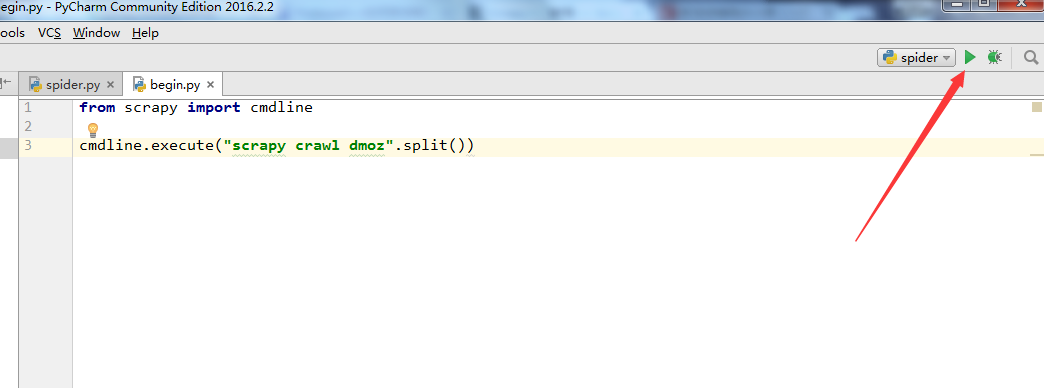
调试
可以在其他代码中设置断点,就可以debug运行

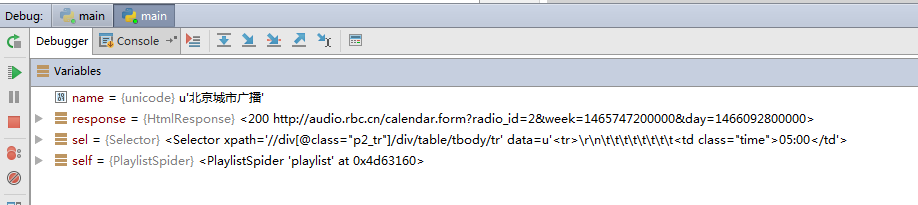
遇到问题
1. Unknown command: crawl
调试运行,断点并未命中,控制台输出信息如下:
H:\Python\Python36\python.exe "H:\Program Files (x86)\JetBrains\PyCharm Community Edition 4.5.4\helpers\pydev\pydevd.py" --multiproc --client 127.0.0.1 --port 59810 --file H:/Python/Python36/Lib/site-packages/scrapy/cmdline.py crawl quotes -o quotes.jl pydev debugger: process 4740 is connecting Connected to pydev debugger (build 141.3058) Scrapy 1.3.2 - no active project Unknown command: crawl Use "scrapy" to see available commands Process finished with exit code 2
工作目录设置有误,造成无法识别 scrapy 命令,按照上文所说,将工作目录设置为包含 scrapy.cfg,重新运行,问题解决。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。