yipeiwu_com6年前
你是否苦恼于网上无法下载的“小说在线阅读”内容?或是某些文章的内容让你很有收藏的冲动,却找不到一个下载的链接?是不是有种自己写个程序把全部搞定的冲动?是不是学了 python,想要找点东...
yipeiwu_com6年前
一般来说,使用线程有两种模式, 一种是创建线程要执行的函数, 把这个函数传递进Thread对象里,让它来执行. 另一种是直接从Thread继承,创建一个新的class,把线程执行的代码放...
yipeiwu_com6年前
网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一...
yipeiwu_com6年前
开发工具:python3.4 操作系统:win8 主要功能:去指定小说网页爬小说目录,按章节保存到本地,并将爬过的网页保存到本地配置文件。 被爬网站:http://www.cishuge...
yipeiwu_com6年前
安卓最美应用页面爬虫,爬虫很简单,设计的东西到挺多的 文件操作 正则表达式 字符串替换等等 import requests import re url = "http://zuime...
yipeiwu_com6年前
花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下 import urllib, urllib2, re, sys...
yipeiwu_com6年前
本文实例讲述了Python实现周期性抓取网页内容的方法。分享给大家供大家参考,具体如下: 1.使用sched模块可以周期性地执行指定函数 2.在周期性执行指定函数中抓取指定网页,并解析出...
yipeiwu_com6年前
1.准备工作: 工欲善其事必先利其器,因此我们有必要在进行Coding前先配置一个适合我们自己的开发环境,我搭建的开发环境是: 操作系统:Ubuntu 14.04 LTS Pytho...
yipeiwu_com6年前
在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情。 #-*-coding:utf-8-*- import os import...
yipeiwu_com6年前
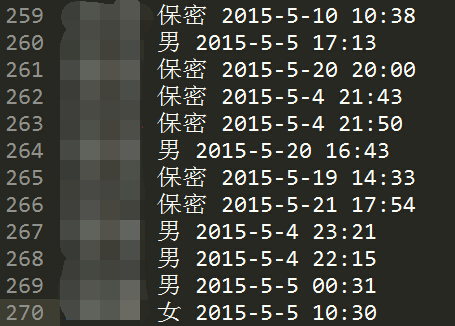
一、项目需求 前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。 经过检查,BBS注册用户的id对应1-300000,大概是30万的用户 笔者想用Pyth...