Python实现周期性抓取网页内容的方法
本文实例讲述了Python实现周期性抓取网页内容的方法。分享给大家供大家参考,具体如下:
1.使用sched模块可以周期性地执行指定函数
2.在周期性执行指定函数中抓取指定网页,并解析出想要的网页内容,代码中是六维论坛的在线人数
论坛在线人数统计代码:
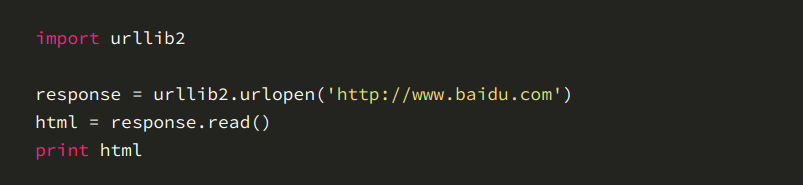
#coding=utf-8
import time,sched,os,urllib2,re,string
#初始化sched模块的scheduler类
#第一个参数是一个可以返回时间戳的函数,第二个参数可以在定时未到达之前阻塞。
s = sched.scheduler(time.time,time.sleep)
#被周期性调度触发的函数
def event_func():
req = urllib2.Request('http://bt.neu6.edu.cn/')
response = urllib2.urlopen(req)
rawdata = response.read()
response.close()
usernump = re.compile(r'总计 <em>.*?</em> 人在线')
usernummatch = usernump.findall(rawdata)
if usernummatch:
currentnum=usernummatch[0]
currentnum=currentnum[string.index(currentnum,'>')+1:string.rindex(currentnum,'<')]
print "Current Time:",time.strftime('%Y,%m,%d,%H,%M',time.localtime(time.time())),'User num:',currentnum
# 保存结果,供图表工具amcharts使用
result=open('liuvUserNUm','a')
result.write('{year: new Date('+time.strftime('%Y,%m,%d,%H,%M',time.localtime(time.time()))+'),value:'+currentnum+'},\n')
result.close()
#enter四个参数分别为:间隔事件、优先级(用于同时间到达的两个事件同时执行时定序)、被调用触发的函数,给他的参数(注意:一定要以tuple给如,如果只有一个参数就(xx,))
def perform(inc):
s.enter(inc,0,perform,(inc,))
event_func()
def mymain(inc=900):
s.enter(0,0,perform,(inc,))
s.run()
if __name__ == "__main__":
mymain()
希望本文所述对大家Python程序设计有所帮助。