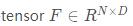yipeiwu_com6年前
SQLAlchemy是Python编程语言下的一款开源软件,提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。SQLAlchemy首次发行于2006年2月,并迅速地在...
yipeiwu_com6年前
基于pytorch来讲 MSELoss()多用于回归问题,也可以用于one_hotted编码形式, CrossEntropyLoss()名字为交叉熵损失函数,不用于one_hotted编...
yipeiwu_com6年前
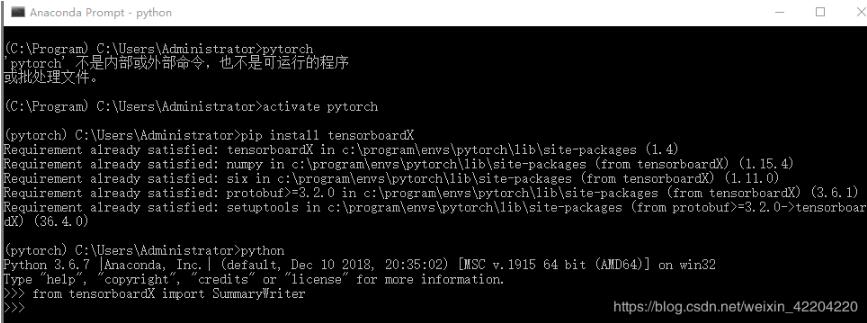
我用的是Anaconda3 ,用spyder编写pytorch的代码,在Anaconda3中新建了一个pytorch的虚拟环境(虚拟环境的名字就叫pytorch)。 以下内容仅供参考哦~...
yipeiwu_com6年前
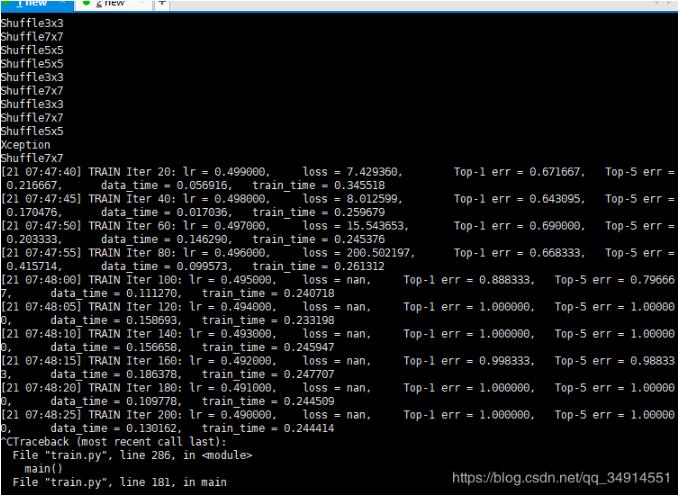
今天使用shuffleNetV2+,使用自己的数据集,遇到了loss是nan的情况,而且top1精确率出现断崖式上升,这显示是不正常的。 在网上查了下解决方案。我的问题是出在学习率上了...
yipeiwu_com6年前
听名字就知道这个函数是用来求tensor中某个dim的前k大或者前k小的值以及对应的index。 用法 torch.topk(input, k, dim=None, largest=...
yipeiwu_com6年前
我们在做迁移学习,或者在分割,检测等任务想使用预训练好的模型,同时又有自己修改之后的结构,使得模型文件保存的参数,有一部分是不需要的(don't expected)。我们搭建的网络对保存...
yipeiwu_com6年前
Pytorch中,变量参数,用numel得到参数数目,累加 def get_parameter_number(net): total_num = sum(p.numel() fo...
yipeiwu_com6年前
基类(商品类及分类类之间共同的字段) class BaseModle(models.Model): name = models.CharField(max_length=32,...
yipeiwu_com6年前
在使用pytorch训练模型,经常需要加载大量图片数据,因此pytorch提供了好用的数据加载工具Dataloader。 为了实现小批量循环读取大型数据集,在Dataloader类具体实...
yipeiwu_com6年前
今天接到一个小需求,就是想在windows环境下,上传压缩文件到linux指定的目录位置并且解压出来,然后我想了一下,这个可以用python试试写下。 环境: 1.linux操作系统一台...