Pytorch训练过程出现nan的解决方式
今天使用shuffleNetV2+,使用自己的数据集,遇到了loss是nan的情况,而且top1精确率出现断崖式上升,这显示是不正常的。
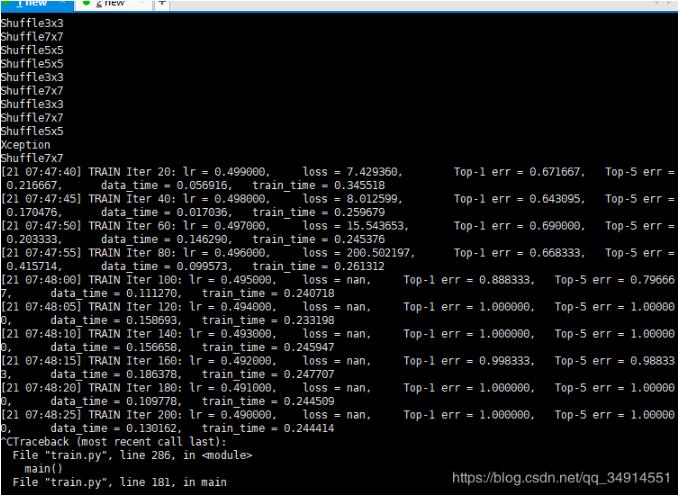
在网上查了下解决方案。我的问题是出在学习率上了。
我自己做的样本数据集比较小,就三类,每类大概三百多张,初始学习率是0.5。后来设置为0.1就解决了。
按照解决方案上写的。出现nan的情况还有以下几种:
学习率太大,但是样本数据集又很小。(我的情况)
自定义的loss除以了一个很小的数字,小到接近0。
数据不干净,数据本身就有nan,可以用numpy.isnan检查。
target,即label是大于等于0的。从1到类别数目-1变化。
以上这篇Pytorch训练过程出现nan的解决方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。

