yipeiwu_com6年前
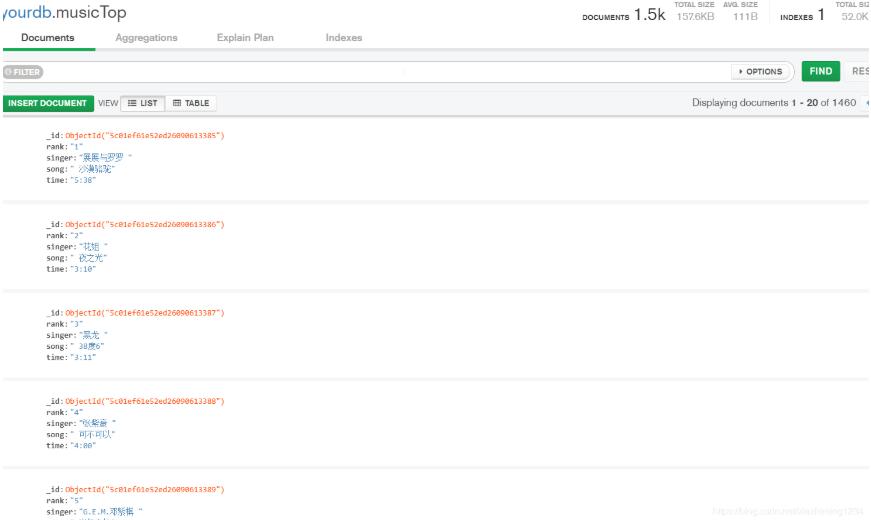
爬取TOP500的音乐信息,包括排名情况、歌曲名、歌曲时间。 网页版酷狗不能手动翻页进行下一步的浏览,仔细观察第一页的URL: http://www.kugou.com/yy/rank/...
yipeiwu_com6年前
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的...
yipeiwu_com6年前
环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例。 第一步:获取评论 我...
yipeiwu_com6年前
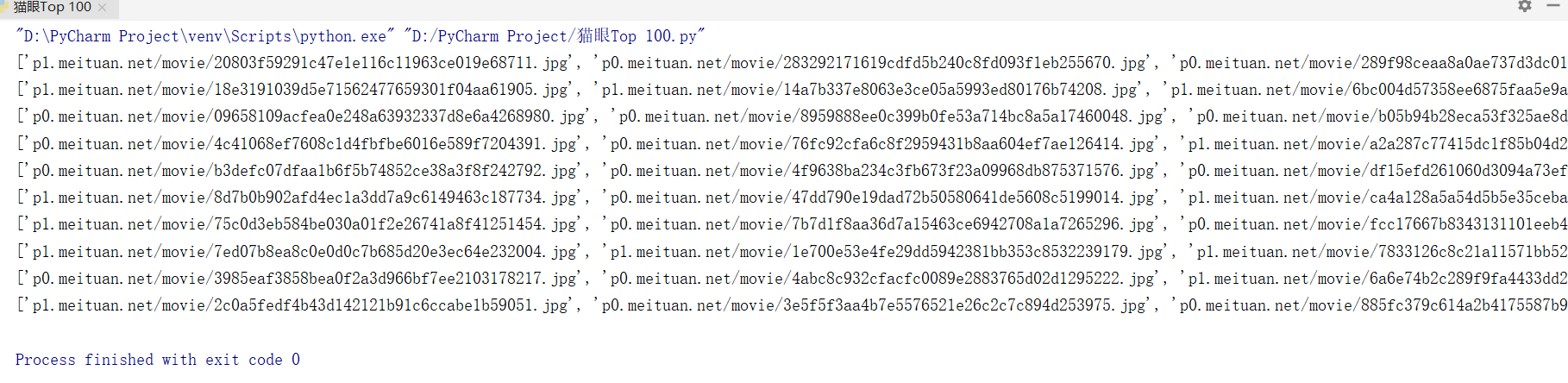
前言 我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像...
yipeiwu_com6年前
本文实例讲述了python实现的爬取电影下载链接功能。分享给大家供大家参考,具体如下: #!/usr/bin/python #coding=UTF-8 import sys impo...
yipeiwu_com6年前
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术...
yipeiwu_com6年前
2019中国好声音火热开播,作为一名“假粉丝”,这一季每一期都刷过了,尤其刚播出的第六期开始正式的battle。视频视频看完了,那看下大家都是怎样评论的。 1.网页分析部分 本文爬取的...
yipeiwu_com6年前
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例...
yipeiwu_com6年前
本文实例为大家分享了selenium+PhantomJS爬取豆瓣读书的具体代码,供大家参考,具体内容如下 获取关于Python的全部书籍信息; 通过代码测试 request携带‘User...
yipeiwu_com6年前
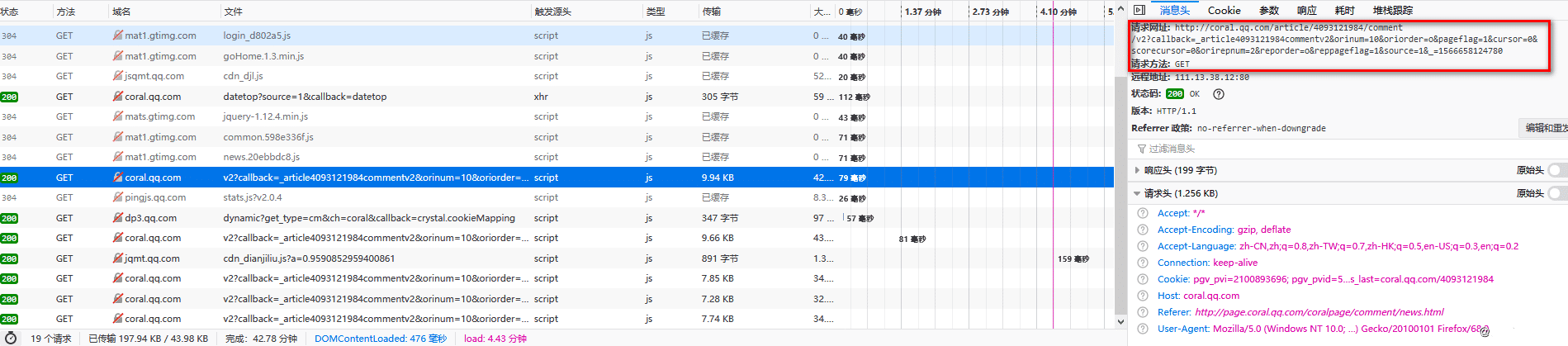
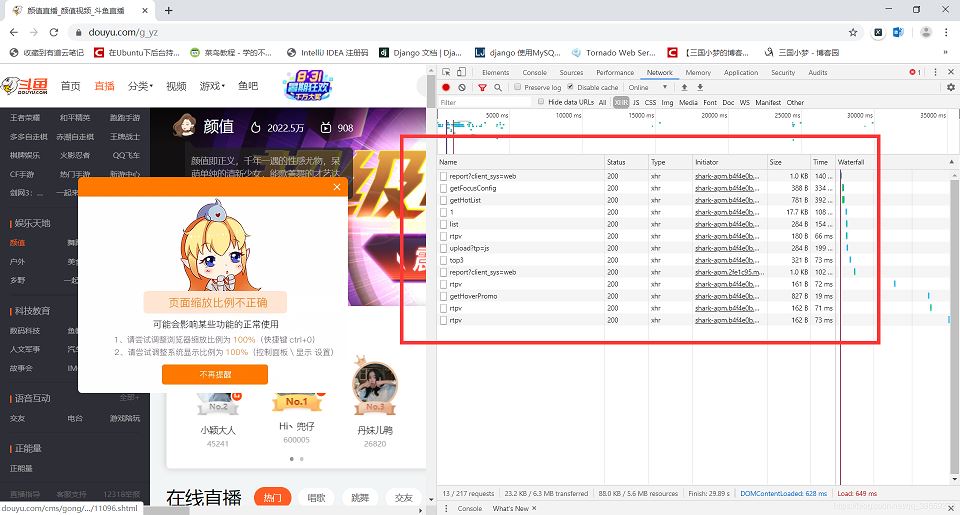
分析 分析网站寻找需要的网址 用谷歌浏览器摁F12打开开发者工具,然后打开斗鱼颜值分类的页面,如图: 在里面的请求中,最后发现它是以ajax加载的数据,数据格式为json,如图: 圈...