yipeiwu_com6年前
常见的反爬机制及处理方式 1、Headers反爬虫 :Cookie、Referer、User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法...
yipeiwu_com6年前
字符串常用方法 # 去掉左右空格 'hello world'.strip() # 'hello world' # 按指定字符切割 'hello world'.split(' ')...
yipeiwu_com6年前
前言 网络爬虫也称为网络蜘蛛、网络机器人,抓取网络的数据。其实就是用Python程序模仿人点击浏览器并访问网站,而且模仿的越逼真越好。一般爬取数据的目的主要是用来做数据分析,或者公司项目...
yipeiwu_com6年前
前言 Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的初级阶段,添加headers和ip代理可...
yipeiwu_com6年前
这篇文章主要介绍了python智联招聘爬虫并导入到excel代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 写了一个智联招聘的...
yipeiwu_com6年前
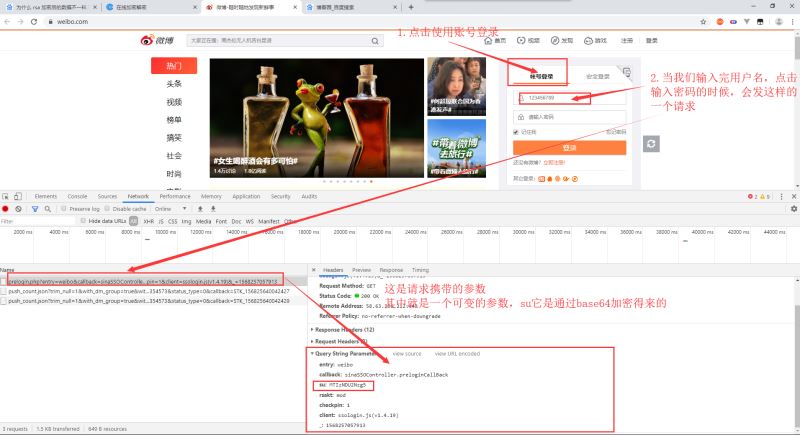
微博模拟登录 这是本次爬取的网址:https://weibo.com/ 一、请求分析 找到登录的位置,填写用户名密码进行登录操作 看看这次请求响应的数据是什么 这是响应得到的数据,保...
yipeiwu_com6年前
本文实例讲述了Python实现的爬取豆瓣电影信息功能。分享给大家供大家参考,具体如下: 本案例的任务为,爬取豆瓣电影top250的电影信息(包括序号、电影名称、导演和主演、评分以及经典台...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能。分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main(...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能。分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,...
yipeiwu_com6年前
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能。分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny'...