yipeiwu_com6年前
目的:在百度贴吧输入关键字和要查找的起始结束页,获取帖子里面楼主所发的图片 思路: 获取分页里面的帖子链接列表 获取帖子里面楼主所发的图片链接列表 保存图片到本地 注意事...
yipeiwu_com6年前
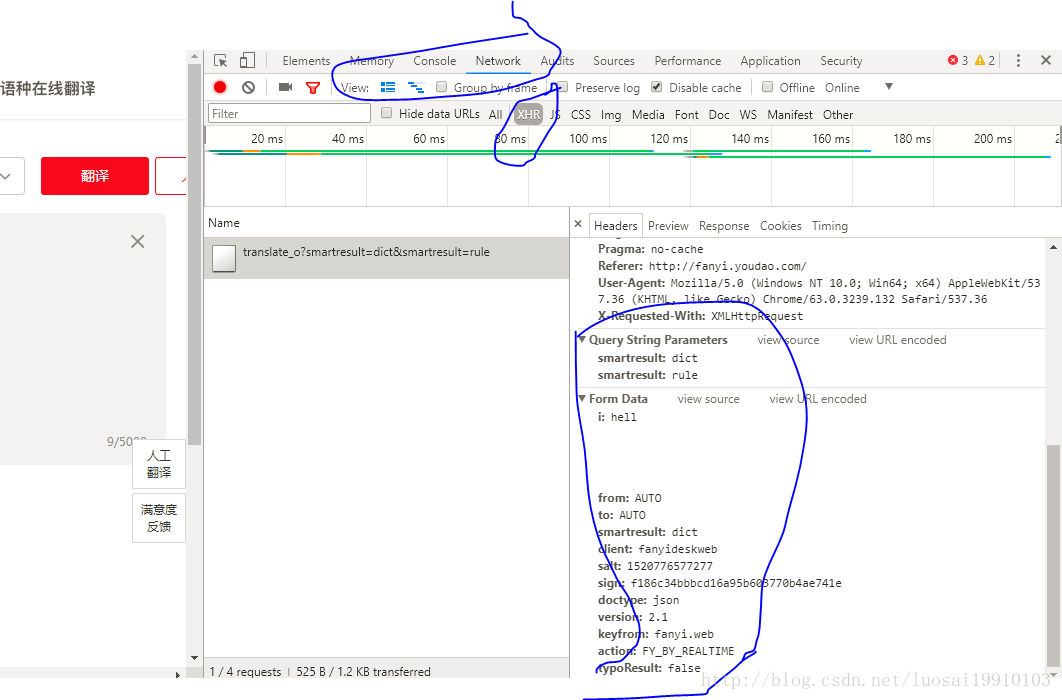
前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上...
yipeiwu_com6年前
创建爬虫项目douban scrapy startproject douban 设置items.py文件,存储要保存的数据类型和字段名称 # -*- coding: utf-8...
yipeiwu_com6年前
最近学习了一些爬虫技术,想做个小项目检验下自己的学习成果,在逛某东的时候,突然给我推荐一个TT的产品,点击进去浏览一番之后就产生了抓取TT产品,然后进行数据分析,看下那个品牌的TT卖得最...
yipeiwu_com6年前
目前很多网站都使用ajax技术动态加载数据,和常规的网站不一样,数据时动态加载的,如果我们使用常规的方法爬取网页,得到的只是一堆html代码,没有任何的数据。 请看下面的代码: ur...
yipeiwu_com6年前
今天一起学起使用selenium和pyquery爬取京东的商品列表。本文的所有代码是在pycharm IDE中完成的,操作系统window 10。 1、准备工作 安装pyquery和s...
yipeiwu_com6年前
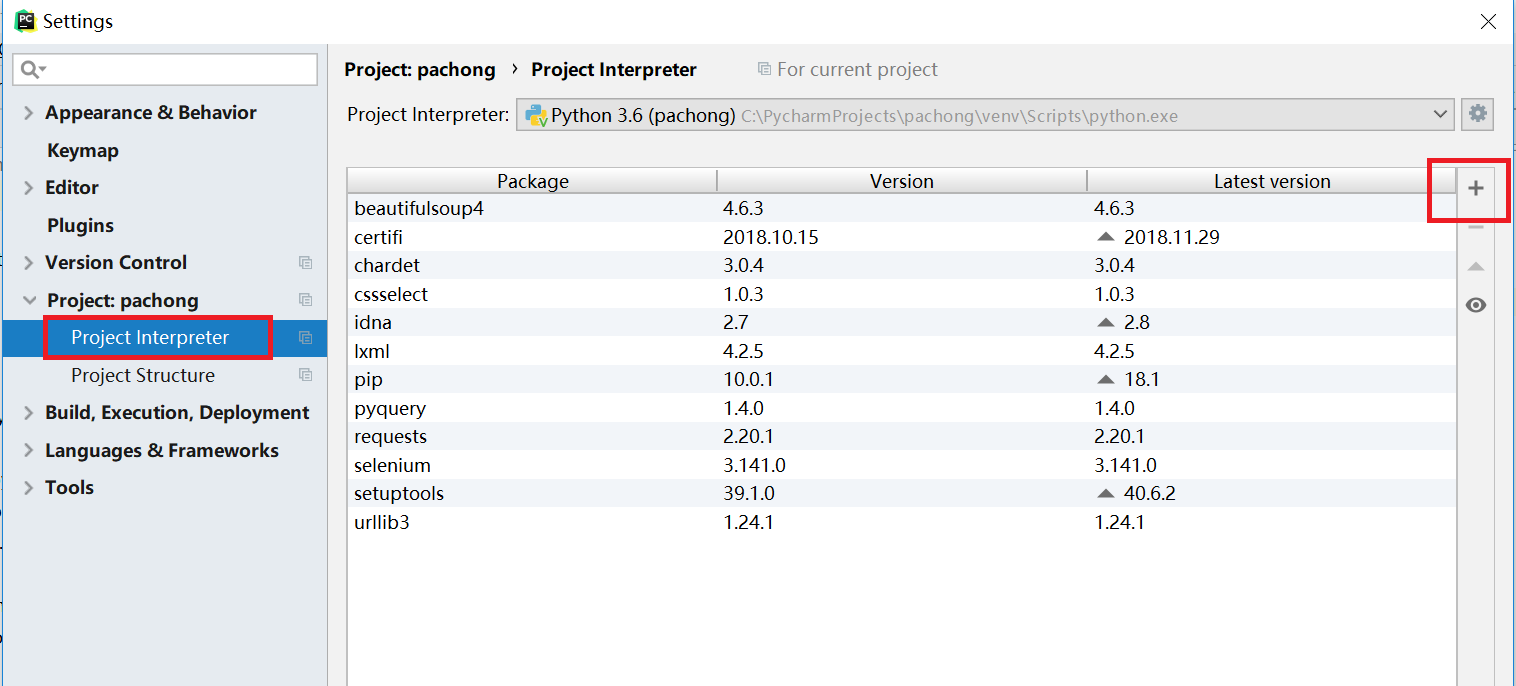
最近在使用爬虫爬取数据时,经常会返回403代码,大致意思是该IP访问过于频繁,被限制访问。限制IP访问网站最常用的反爬手段了,其实破解也很容易,就是在爬取网站是使用代理即可,这个IP被限...
yipeiwu_com6年前
前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beau...
yipeiwu_com6年前
简介 壁纸的选择其实很大程度上能看出电脑主人的内心世界,有的人喜欢风景,有的人喜欢星空,有的人喜欢美女,有的人喜欢动物。然而,终究有一天你已经产生审美疲劳了,但你下定决定要换壁纸的时候...
yipeiwu_com6年前
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 pyth...