yipeiwu_com6年前
如果直接从生成验证码的页面把验证码下载到本地后识别,再构造表单数据发送的话,会有一个验证码同步的问题,即请求了两次验证码,而识别出来的验证码并不是实际需要发送的验证码。有如下几种方法解决...
yipeiwu_com6年前
窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案。 到上面去看了看,地址都是明文的,得,赶紧开始吧。 下载流式文件,re...
yipeiwu_com6年前
看着自己少得可怜的访问量,突然有一个想用爬虫刷访问量的想法,主要也是抱着尝试的心态,学习学习。 其实市面上有一些软件可以代刷流量 比如 流量精灵,使用感确实比我们自己写的代码要好一些 第...
yipeiwu_com6年前
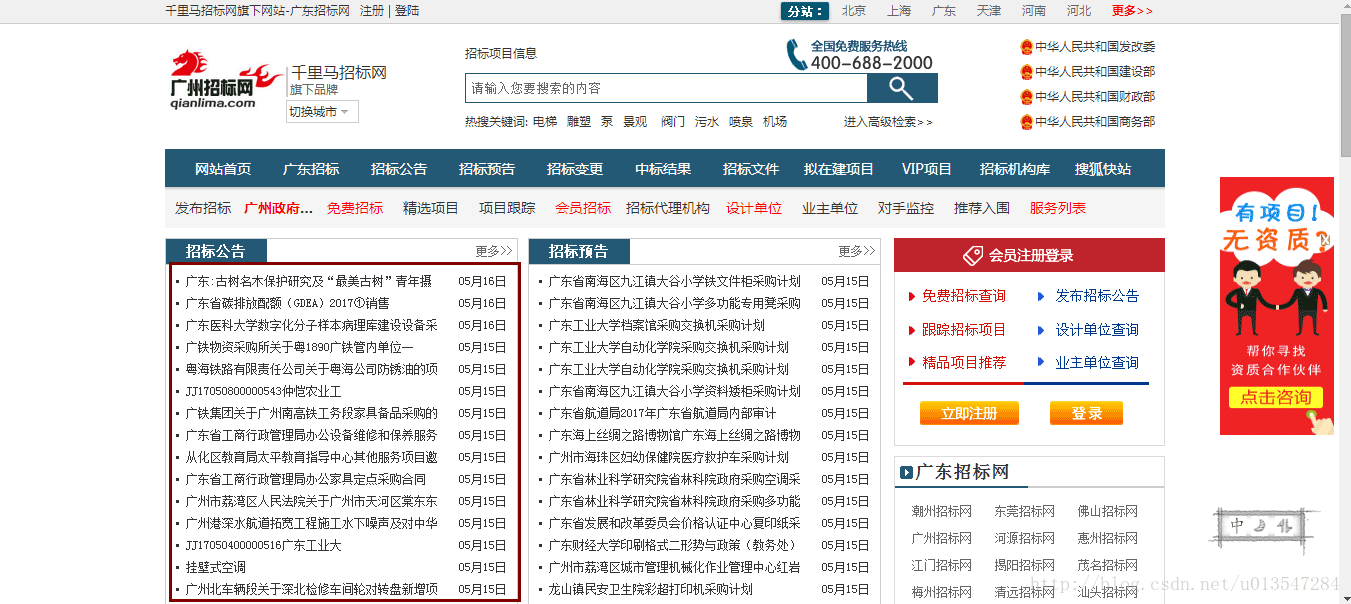
本文实例讲述了Python基于BeautifulSoup和requests实现的爬虫功能。分享给大家供大家参考,具体如下: 爬取的目标网页:http://www.qianlima.com...
yipeiwu_com6年前
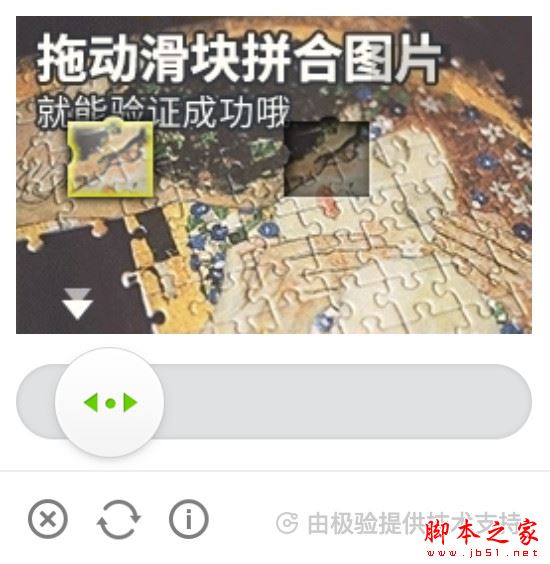
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合...
yipeiwu_com6年前
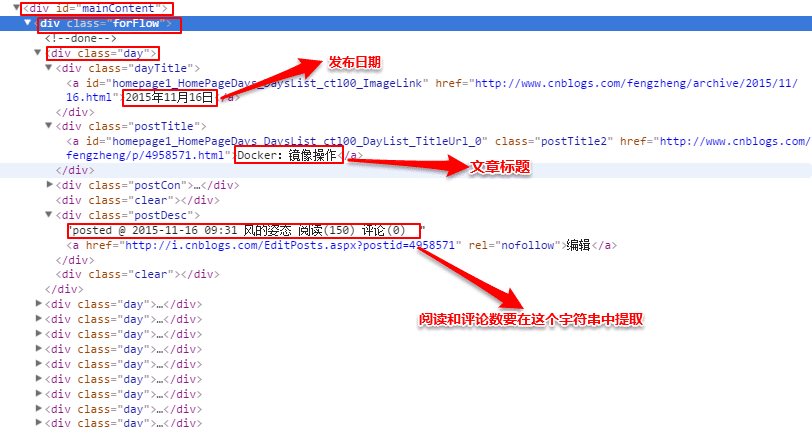
前言 python中常用的写爬虫的库常有urllib2、requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现。这里有一篇我之前写过的用urllib2+Beaut...
yipeiwu_com6年前
1.selenum:三方库。可以实现让浏览器完成自动化的操作。 2.环境搭建 2.1 安装: pip install selenium 2.2 获取浏览器的驱动程序 下载地址...
yipeiwu_com6年前
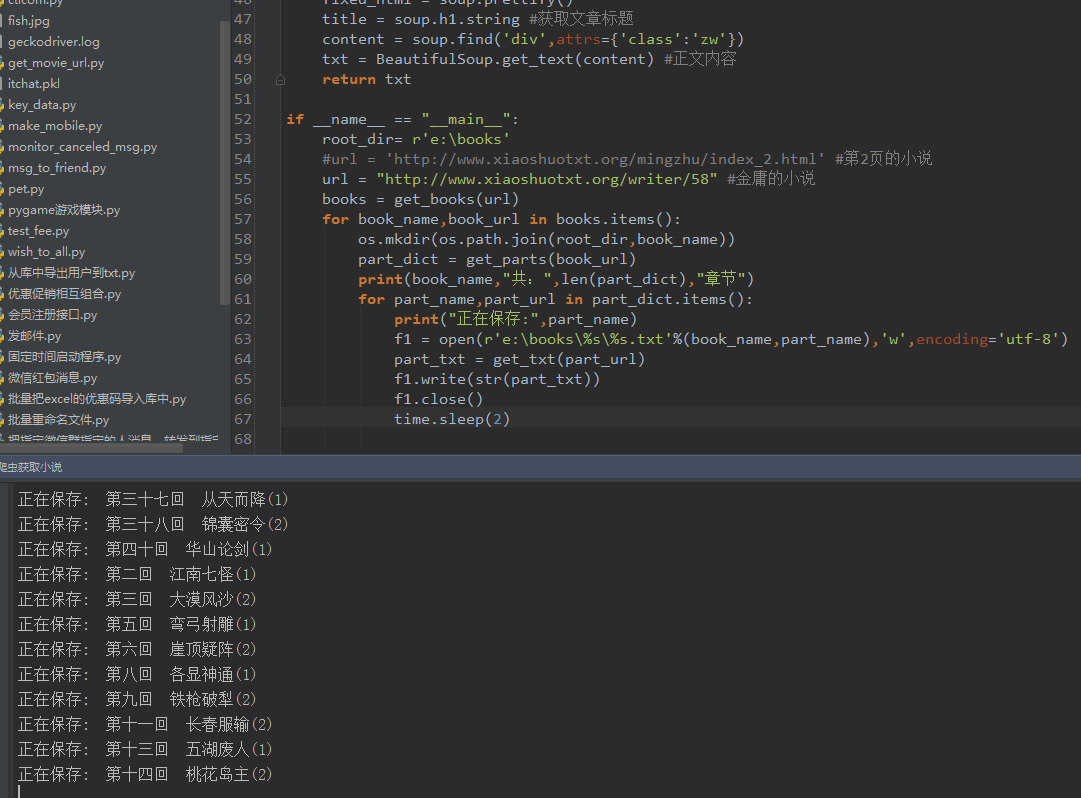
本文实例讲述了python实现爬虫抓取小说功能。分享给大家供大家参考,具体如下: # -*- coding: utf-8 -*- from bs4 import BeautifulS...
yipeiwu_com6年前
还是分析一下大体的流程: 首先还是Chrome浏览器抓包分析元素,这是网址:https://www.douyu.com/directory/all 发现所有房间的信息都是保存在一个无...
yipeiwu_com6年前
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search...