yipeiwu_com6年前
本文实例讲述了Python爬虫实现抓取京东店铺信息及下载图片功能。分享给大家供大家参考,具体如下: 这个是抓取信息的 from bs4 import BeautifulSoup im...
yipeiwu_com6年前
本文实例讲述了Python爬虫之pandas基本安装与使用方法。分享给大家供大家参考,具体如下: 一、简介: Python Data Analysis Library 或 pandas...
yipeiwu_com6年前
本文实例讲述了Python爬虫之正则表达式基本用法。分享给大家供大家参考,具体如下: 一、简介 正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regu...
yipeiwu_com6年前
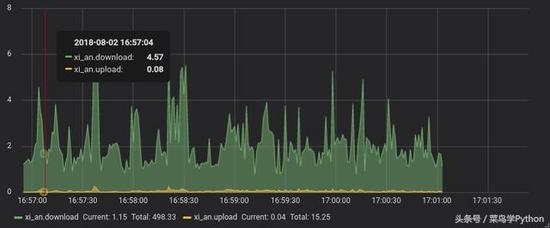
今天主要是来说一下怎么可视化来监控你的爬虫的状态。 相信大家在跑爬虫的过程中,也会好奇自己养的爬虫一分钟可以爬多少页面,多大的数据量,当然查询的方式多种多样。今天我来讲一种可视化的方法。...
yipeiwu_com6年前
具体代码如下所示: #coding:utf-8 #!/usr/bin/python3 from selenium import webdriver import time impo...
yipeiwu_com6年前
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法。分享给大家供大家参考,具体如下: 图片资源来自于www.qiubaichengren.com 代码基于Python 3....
yipeiwu_com6年前
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import requests from bs...
yipeiwu_com6年前
本文实例为大家分享了python使用webdriver爬取微信公众号的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- from seleniu...
yipeiwu_com6年前
设置代理IP的原因 我们在使用Python爬虫爬取一个网站时,通常会频繁访问该网站。假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置...
yipeiwu_com6年前
前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 X...