yipeiwu_com6年前
关于这篇文章有几句话想说,首先给大家道歉,之前学的时候真的觉得下述的是比较厉害的东西,但是后来发现真的是基础中的基础,内容还不是很完全。再看一遍自己写的这篇文章,突然有种想自杀的冲动。e...
yipeiwu_com6年前
会用到的功能的简单介绍 1、from bs4 import BeautifulSoup #导入库 2、请求头herders headers={'User-Agent': 'Mo...
yipeiwu_com6年前
该爬虫应用了创建文件夹的功能: #file setting folder_path = "D:/spider_things/2016.4.6/" + file_name +"/" i...
yipeiwu_com6年前
本文实例讲述了python爬虫之线程池和进程池功能与用法。分享给大家供大家参考,具体如下: 一、需求 最近准备爬取某电商网站的数据,先不考虑代理、分布式,先说效率问题(当然你要是请求的太...
yipeiwu_com6年前
本文实例讲述了python爬虫框架scrapy实现模拟登录操作。分享给大家供大家参考,具体如下: 一、背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML、...
yipeiwu_com6年前
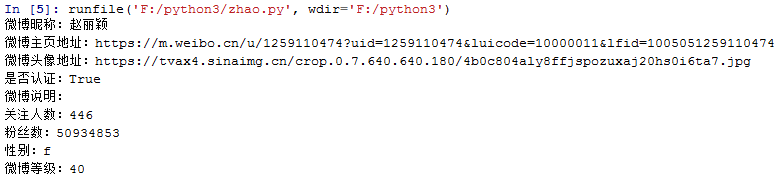
本文实例讲述了Python爬虫爬取新浪微博内容。分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.w...
yipeiwu_com6年前
本文实例讲述了Python爬取个人微信朋友信息操作。分享给大家供大家参考,具体如下: 利用Python的itchat包爬取个人微信号的朋友信息,并将信息保存在本地文本中 思路要点: 1....
yipeiwu_com6年前
本文实例讲述了Python爬虫框架scrapy实现的文件下载功能。分享给大家供大家参考,具体如下: 我们在写普通脚本的时候,从一个网站拿到一个文件的下载url,然后下载,直接将数据写入文...
yipeiwu_com6年前
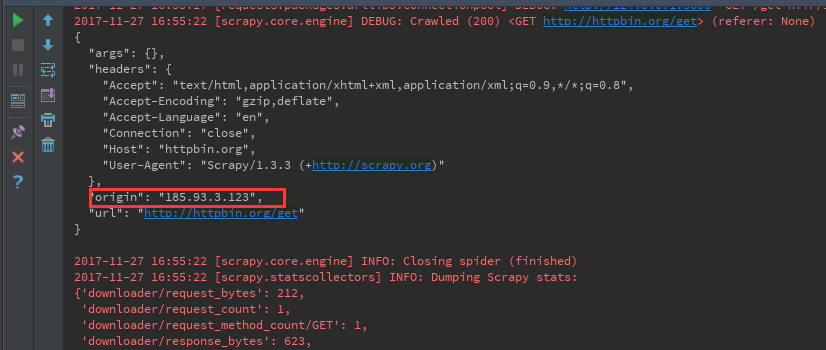
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能。分享给大家供大家参考,具体如下: 一、背景: 小编在爬虫的时候肯定会遇...
yipeiwu_com6年前
本文实例讲述了Python爬虫PyQuery库基本用法。分享给大家供大家参考,具体如下: PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQue...