Python爬虫基础之XPath语法与lxml库的用法详解
前言
本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法
XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言。
XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。 XPath 同样也支持HTML。
XPath 是一门小型的查询语言。
python 中 lxml库 使用的是 Xpath 语法,是效率比较高的解析方法。
下面话不多说了,来一起看看详细的介绍吧
安装
为什么要用这个库呢,因为要写爬虫啊,利用lxml库来解析 HTML 代码,同时lxml也继承了libxml2的特性自动修正HTML代码,利用pip安装即可
pip install lxml
XPath语法
XPath是一门在XML文档中查找信息的语言,可以用于在XML文档中通过元素和属性进行导航
举个栗子 😎
我们可以使用XPath提取网站地图中的所有链接,也就是说可以使用XPath去找我们HTML中的一些具体的东西
节点关系
在XPath中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)
再举个栗子 😎
<urlset> <url> <loc>https://qq52o.me</loc> <lastmod>2018-04-28T19:00:42+00:00</lastmod> <changefreq>daily</changefreq> <priority>1.0</priority> </url> </urlset>
第一个:父(Parent)
每个元素以及属性都有一个父
url元素是 loc、lastmod、changefreq以及 priority元素的父
第二个:子(Children)
元素节点可有零个、一个或多个子
loc、lastmod、changefreq以及 priority元素都是url元素的子
第三个:同胞(Sibling)
拥有相同的父的节点
loc、lastmod、changefreq以及 priority元素都是url元素的同胞
第四个:先辈(Ancestor)
某节点的父、父的父,等等
loc元素的先辈是 url元素和 urlset元素
第五个:后代(Descendant)
某个节点的子,子的子,等等
urlset的后代是url、loc、lastmod、changefreq以及 priority元素
如果你分不清楚,就按照子元素从上到下的去找元素节点
选取节点
XPath使用路径表达式在 XML 文档中选取节点,节点是通过沿着路径或者 step 来选取的,也就是上面所说的按照子元素从上到下去找元素节点
这些是最有用的路径表达式 💡
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
实例
| 路径表达式 | 结果 |
|---|---|
| urlset | 选取urlset元素的所有子节点 |
| /urlset | 选取根元素 urlset |
| urlset/url | 选取属于urlset的子元素的所有url元素 |
| //url | 选取所有url子元素,而不管它们在文档中的位置 |
| urlset//url | 选择属于urlset元素的后代的所有url元素,而不管它们位于urlset之下的什么位置 |
| //@href | 选取名为href的所有属性 |
其他XPath语法请参考w3school
XPath实例测试
提取本站网站地图中id属性为content的的子元素h3的内容以及子元素a的href属性,F12去看代码找这个属性

div的id属性,下面的子元素h3的内容,直接利用 text 方法来获取元素的内容,然后输出
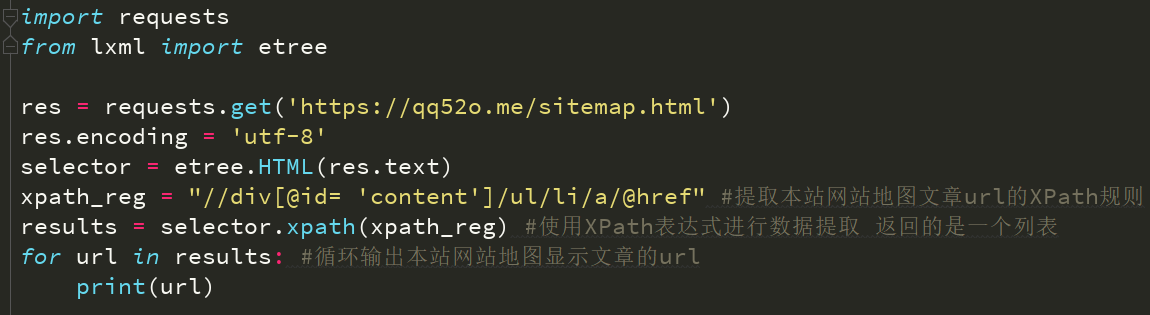
这里的子元素层级关系必须按顺序写好,不然会报错的
IndexError: list index out of range
这就说明你的XPath规则没写好,list是一个空的,没有一个元素
XPath 是一个非常好用的解析方法,同时也是作为爬虫学习的基础
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。