Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法。分享给大家供大家参考,具体如下:
图片资源来自于www.qiubaichengren.com
代码基于Python 3.5.2
友情提醒:血气方刚的骚年。请
谨慎阅图!
谨慎阅图!!
谨慎阅图!!!
code:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import urllib
import urllib.request
import re
from urllib.error import URLError
class QsSpider:
def __init__(self):
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
self.header = {'User-Agent': self.user_agent}
self.save_dir = './pic'
self.url = 'http://www.qiubaichengren.com/%s.html'
def start(self):
for i in range(1, 10):
self.load_html(str(i))
def load_html(self, page):
try:
web_path = self.url % page
request = urllib.request.Request(web_path, headers=self.header)
with urllib.request.urlopen(request) as f:
html_content = f.read().decode('gb2312')
# print(html_content)
self.pick_pic(html_content)
except URLError as e:
print(e.reason)
return
def save_pic(self, img):
print(img)
save_path = self.save_dir + "/" + img.replace(':', '@').replace('/', '_')
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
print(save_path)
urllib.request.urlretrieve(img, save_path)
pass
def pick_pic(self, html_content):
regex = r'src="(http:.*?\.(?:jpg|png|gif))'
patten = re.compile(regex)
pic_path_list = patten.findall(html_content)
for i in pic_path_list:
self.save_pic(str(i))
print(i)
spider = QsSpider()
spider.start()
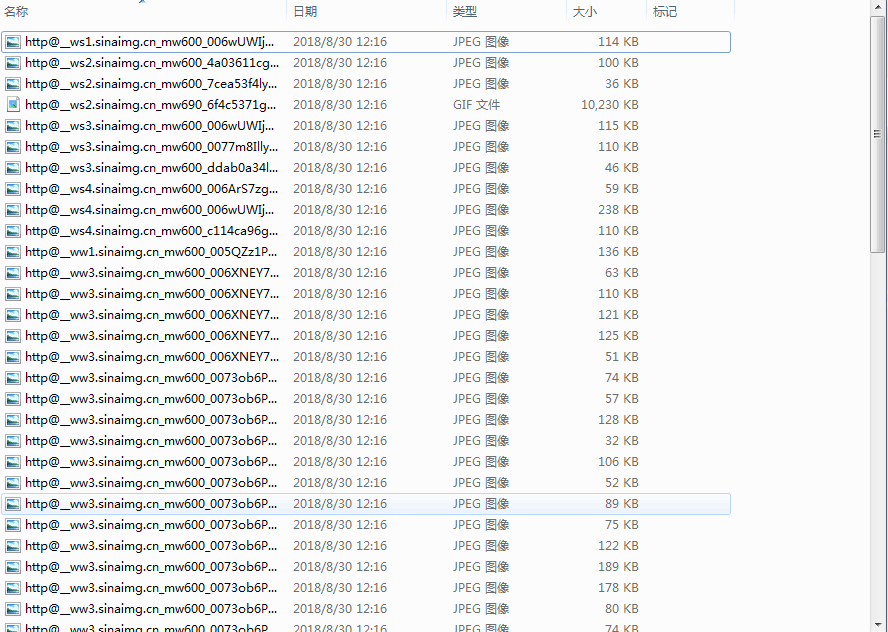
代码运行后可得到如下N多大饱眼福的美女图:
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。