使用Python的Scrapy框架十分钟爬取美女图
简介
scrapy 是一个 python 下面功能丰富、使用快捷方便的爬虫框架。用 scrapy 可以快速的开发一个简单的爬虫,官方给出的一个简单例子足以证明其强大:
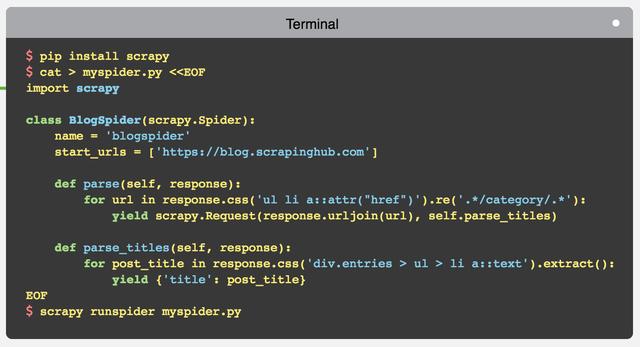
快速开发
下面开始10分钟倒计时:
当然开始前,可以先看看之前我们写过的 scrapy 入门文章 《零基础写python爬虫之使用Scrapy框架编写爬虫
1. 初始化项目
scrapy startproject mzt cd mzt scrapy genspider meizitu meizitu.com
2. 添加 spider 代码:
定义 scrapy.Item ,添加 image_urls 和 images ,为下载图片做准备。
修改 start_urls 为初始页面, 添加 parse 用于处理列表页, 添加 parse_item 处理项目页面。
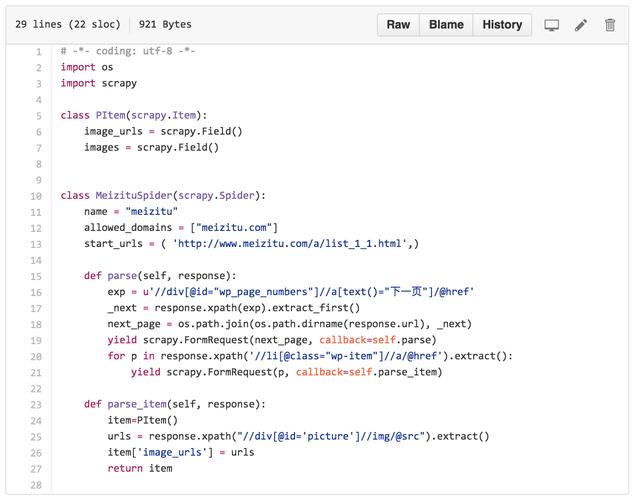
3. 修改配置文件:
DOWNLOAD_DELAY = 1 # 添加下载延迟配置
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1} # 添加图片下载 pipeline
IMAGES_STORE = '.' # 设置图片保存目录
4. 运行项目:
scrapy crawl meizitu
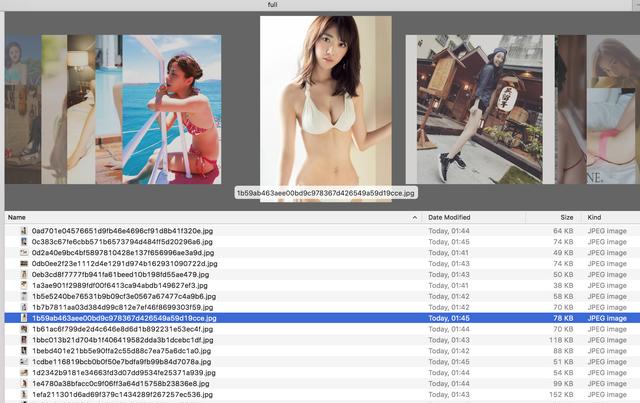
看,项目运行效果图
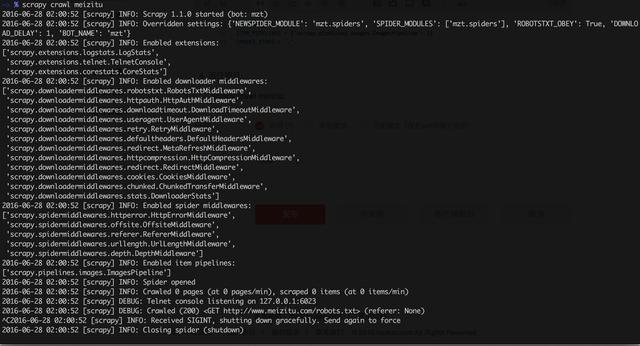
等待一会儿,就是收获的时候了

总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。