yipeiwu_com6年前
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力——个人比较懒。花了几天写了写,本着想完成验证码的...
yipeiwu_com6年前
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看。爬虫用的是python3.3开发的,主要用到了urllib、request和BeautifulSoup模块。 urllib模块...
yipeiwu_com6年前
我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装、下载、运行起来不会花你5分钟时间。 # -*- coding: utf-8...
yipeiwu_com6年前
Windows下的安装: 下载地址:https://pypi.python.org/pypi/pyquery/#downloads 下载后安装: C:\Python27>ea...
yipeiwu_com6年前
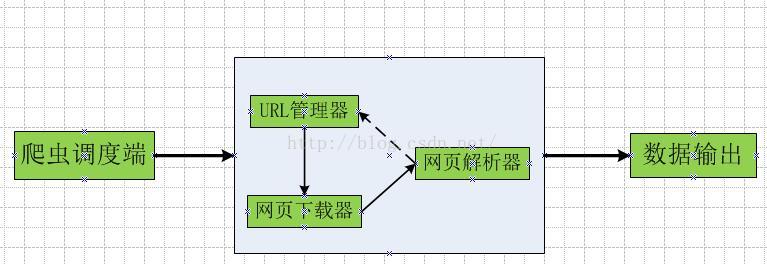
聊一聊Python与网络爬虫。 1、爬虫的定义 爬虫:自动抓取互联网数据的程序。 2、爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若...
yipeiwu_com6年前
先把要抓取的网络地址列在单独的list文件中 //www.jb51.net/article/83440.html //www.jb51.net/article/83437.html...
yipeiwu_com6年前
最近需要爬取某网站,无奈页面都是JS渲染后生成的,普通的爬虫框架搞不定,于是想到用Phantomjs搭一个代理。 Python调用Phantomjs貌似没有现成的第三方库(如果有,请告知...
yipeiwu_com6年前
本文实例为大家分享了python爬取51job中hr的邮箱具体代码,供大家参考,具体内容如下 #encoding=utf8 import urllib2 import cookie...
yipeiwu_com6年前
Web抓取 Web站点使用HTML描述,这意味着每个web页面是一个结构化的文档。有时从中 获取数据同时保持它的结构是有用的。web站点不总是以容易处理的格式, 如 csv 或者 jso...
yipeiwu_com6年前
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法。分享给大家供大家参考,具体如下: 在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问...