python抓取并保存html页面时乱码问题的解决方法
本文实例讲述了python抓取并保存html页面时乱码问题的解决方法。分享给大家供大家参考,具体如下:
在用Python抓取html页面并保存的时候,经常出现抓取下来的网页内容是乱码的问题。出现该问题的原因一方面是自己的代码中编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码和标示的编码不符合造成的。html页面标示的编码在这里:
复制代码 代码如下:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
这里提供一种简单的办法解决:使用chardet判断网页的真实编码,同时从url请求返回的info判断标示编码。如果两种编码不同,则使用bs模块扩展为GB18030编码;如果相同则直接写入文件(这里设置系统默认编码为utf-8)。
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = '//www.jb51.net'
download(url)
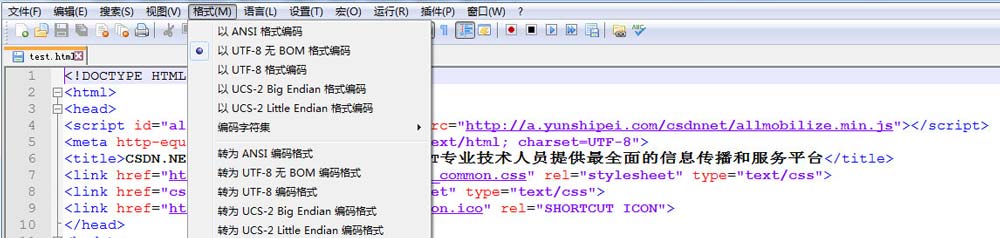
得到的test.html文件打开如下,可以看到使用的是UTF-8无BOM编码格式存储的,也就是我们设置的默认编码:
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。