Python实现抓取页面上链接的简单爬虫分享
除了C/C++以外,我也接触过不少流行的语言,PHP、java、javascript、python,其中python可以说是操作起来最方便,缺点最少的语言了。
前几天想写爬虫,后来跟朋友商量了一下,决定过几天再一起写。爬虫里重要的一部分是抓取页面中的链接,我在这里简单的实现一下。
首先我们需要用到一个开源的模块,requests。这不是python自带的模块,需要从网上下载、解压与安装:
windows用户直接点击下载。解压后再本地使用命令python setup.py install安装即可。 https://github.com/kennethreitz/requests/zipball/master
这个模块的文档我也正在慢慢翻译,翻译完了就给大家传上来(英文版先发在附件里)。就像它的说明里面说的那样,built for human beings,为人类而设计。使用它很方便,自己看文档。最简单的,requests.get()就是发送一个get请求。
代码如下:
# coding:utf-8
import re
import requests
# 获取网页内容
r = requests.get('http://www.163.com')
data = r.text
# 利用正则查找所有连接
link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" ,data)
for url in link_list:
print url
首先import进re和requests模块,re模块是使用正则表达式的模块。
data = requests.get('http://www.163.com'),向网易首页提交get请求,得到一个requests对象r,r.text就是获得的网页源代码,保存在字符串data中。
再利用正则查找data中所有的链接,我的正则写的比较粗糙,直接把href=""或href=''之间的信息获取到,这就是我们要的链接信息。
re.findall返回的是一个列表,用for循环遍历列表并输出:
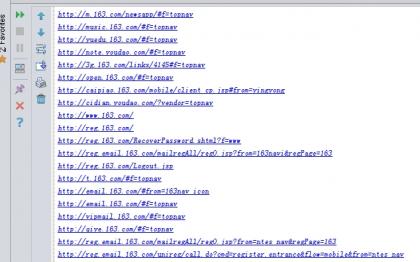
这是我获取到的所有连接的一部分。
上面是获取网站里所有链接的一个简单的实现,没有处理任何异常,没有考虑到超链接的类型,代码仅供参考。requests模块文档见附件。