Python爬取爱奇艺电影信息代码实例
这篇文章主要介绍了Python爬取爱奇艺电影信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
一,使用库
1.requests
2.re
3.json
二,抓取html文件
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
三,解析html文件
我们需要的电影信息的部分如下图(评分,片名,主演):

抓取到的html文件对应的代码:
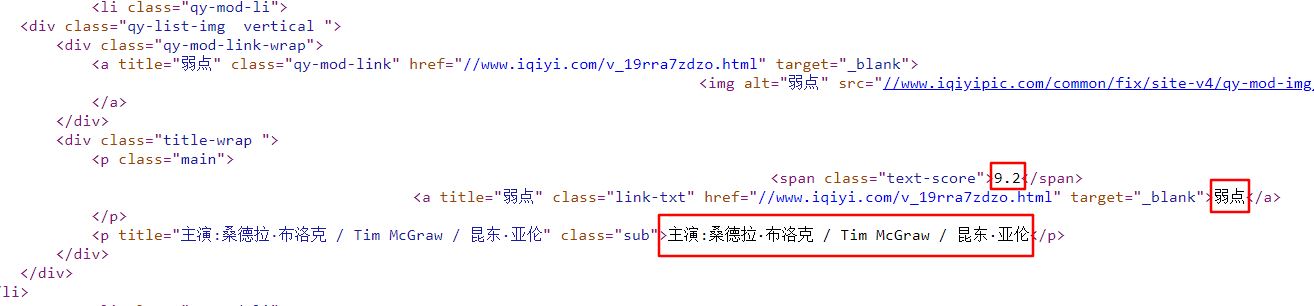
可以分析出,每部电影的信息都在一个<li>标签内,用正则表达式解析:
def parse_page(html):
pattern = re.compile('<li.*?qy-mod-li.*?text-score">(.*?)<.*?title.*?>(.*?)<.*?title.*?>(.*?)<', re.S)
items = re.findall(pattern, html)
for item in items:#转换为字典形式保存
yield {
'score': item[0],
'name': item[1],
'actor': item[2].strip()[3:]#将‘主演:'去掉
}
四,写入文件
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')#将字典格式转换为字符串加以保存,并设置中文格式
f.close()
五,调用函数
def main():
url = 'https://list.iqiyi.com/www/1/-------------8-1-1-iqiyi--.html'
html = get_page(url)
for item in parse_page(html):
print(item)
write_to_file(item)
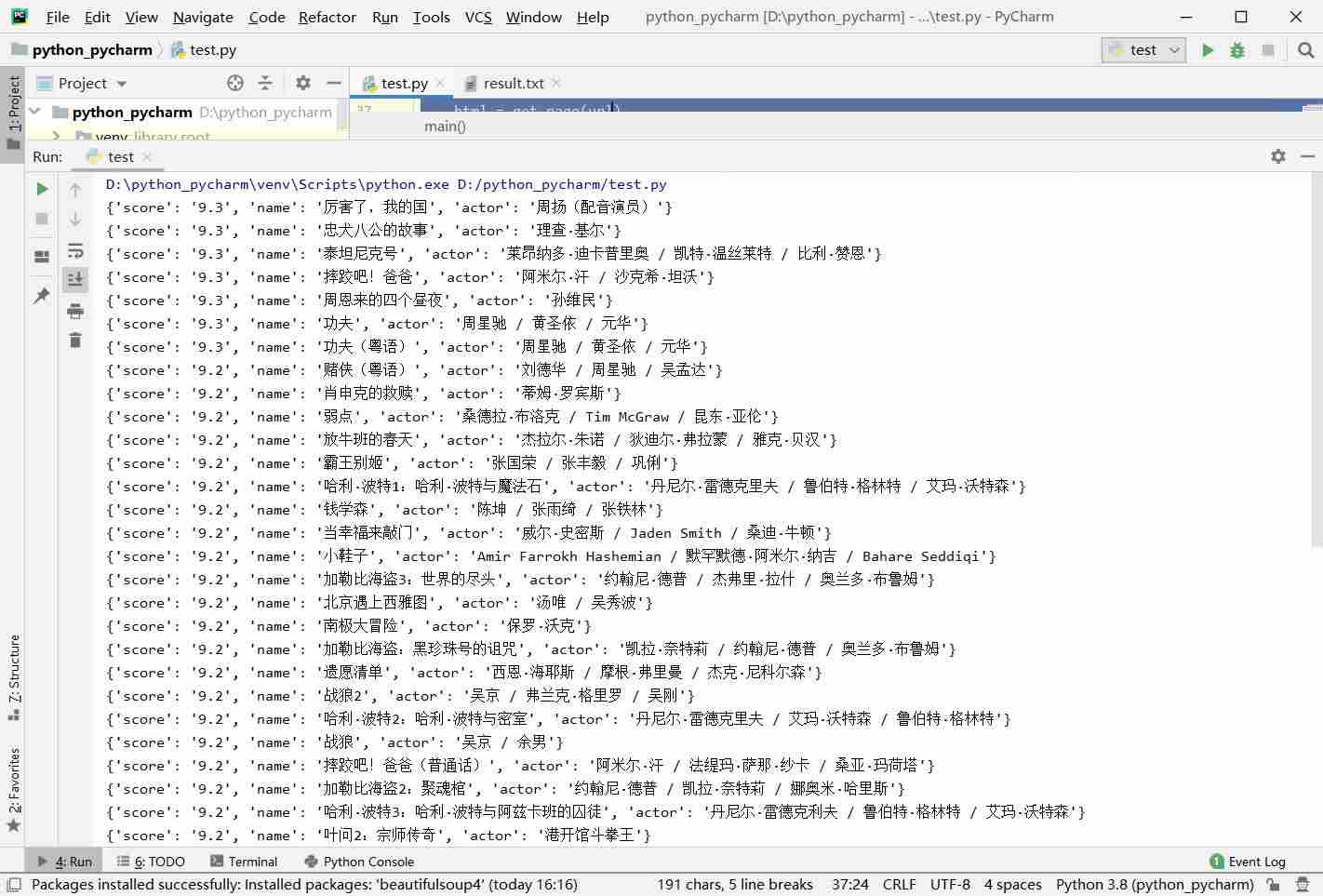
六,运行结果

七,完整代码
import json
import requests
import re
# 抓取html文件
# 解析html文件
# 存储文件
def get_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
def parse_page(html):
pattern = re.compile('<li.*?qy-mod-li.*?text-score">(.*?)<.*?title.*?>(.*?)<.*?title.*?>(.*?)<', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'score': item[0],
'name': item[1],
'actor': item[2].strip()[3:]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
f.close()
def main():
url = 'https://list.iqiyi.com/www/1/-------------8-1-1-iqiyi--.html'
html = get_page(url)
for item in parse_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。