python3写爬取B站视频弹幕功能
需要准备的环境:
一个B站账号,需要先登录,否则不能查看历史弹幕记录
联网的电脑和顺手的浏览器,我用的Chrome
Python3环境以及request模块,安装使用命令,换源比较快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求
点击查看历史弹幕,获取请求


其中rolldate后面的数字表示该视频对应的弹幕号,返回的数据中timestamp表示弹幕日期,new表示数目

在查看历史弹幕中任选一天,查看,会发出新的请求
dmroll ,时间戳,弹幕号,表示获取该日期的弹幕,1507564800 表示2017/10/10 0:0:0


该请求返回xml数据

使用正则表达式获取所有弹幕消息,匹配模式
'<d p=".*?">(.*?)</d>'
拼接字符串,将所有弹幕保存到本地文件即可
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,将弹幕按照日期保存为单个文件...因为太多了...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('<d p=".*?">(.*?)</d>', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
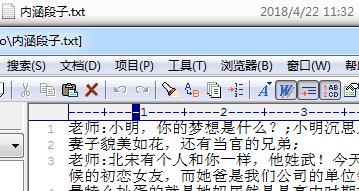
最终效果


之后可以 做一些分词生成词云或者进行情感分析,有时间在说吧....
大家可以在下方给小编留言你学习的心得,也感谢你对【听图阁-专注于Python设计】的支持。