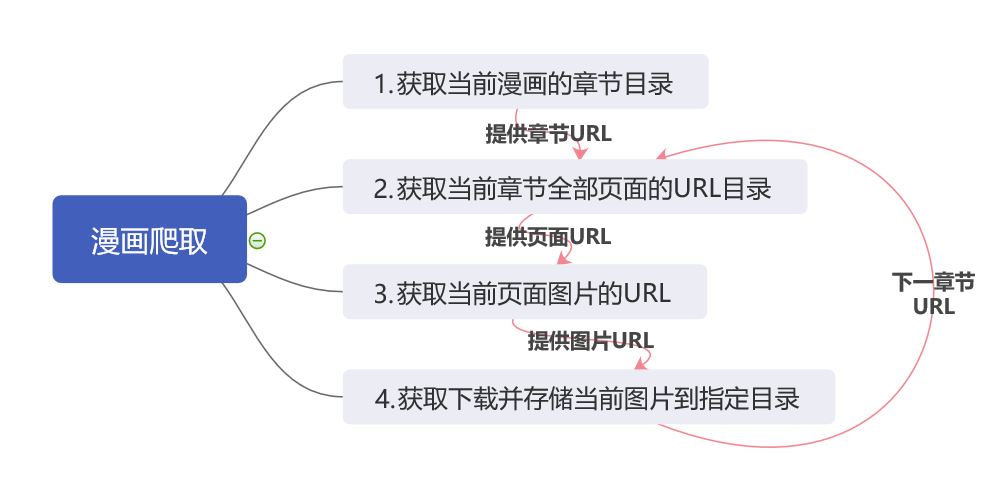
python实现博客文章爬虫示例
#!/usr/bin/python
#-*-coding:utf-8-*-
# JCrawler
# Author: Jam <810441377@qq.com>
import time
import urllib2
from bs4 import BeautifulSoup
# 目标站点
TargetHost = "http://adirectory.blog.com"
# User Agent
UserAgent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.117 Safari/537.36'
# 链接采集规则
# 目录链接采集规则
CategoryFind = [{'findMode':'find','findTag':'div','rule':{'id':'cat-nav'}},
{'findMode':'findAll','findTag':'a','rule':{}}]
# 文章链接采集规则
ArticleListFind = [{'findMode':'find','findTag':'div','rule':{'id':'content'}},
{'findMode':'findAll','findTag':'h2','rule':{'class':'title'}},
{'findMode':'findAll','findTag':'a','rule':{}}]
# 分页URL规则
PageUrl = 'page/#page/'
PageStart = 1
PageStep = 1
PageStopHtml = '404: Page Not Found'
def GetHtmlText(url):
request = urllib2.Request(url)
request.add_header('Accept', "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp")
request.add_header('Accept-Encoding', "*")
request.add_header('User-Agent', UserAgent)
return urllib2.urlopen(request).read()
def ArrToStr(varArr):
returnStr = ""
for s in varArr:
returnStr += str(s)
return returnStr
def GetHtmlFind(htmltext, findRule):
findReturn = BeautifulSoup(htmltext)
returnText = ""
for f in findRule:
if returnText != "":
findReturn = BeautifulSoup(returnText)
if f['findMode'] == 'find':
findReturn = findReturn.find(f['findTag'], f['rule'])
if f['findMode'] == 'findAll':
findReturn = findReturn.findAll(f['findTag'], f['rule'])
returnText = ArrToStr(findReturn)
return findReturn
def GetCategory():
categorys = [];
htmltext = GetHtmlText(TargetHost)
findReturn = GetHtmlFind(htmltext, CategoryFind)
for tag in findReturn:
print "[G]->Category:" + tag.string + "|Url:" + tag['href']
categorys.append({'name': tag.string, 'url': tag['href']})
return categorys;
def GetArticleList(categoryUrl):
articles = []
page = PageStart
#pageUrl = PageUrl
while True:
htmltext = ""
pageUrl = PageUrl.replace("#page", str(page))
print "[G]->PageUrl:" + categoryUrl + pageUrl
while True:
try:
htmltext = GetHtmlText(categoryUrl + pageUrl)
break
except urllib2.HTTPError,e:
print "[E]->HTTP Error:" + str(e.code)
if e.code == 404:
htmltext = PageStopHtml
break
if e.code == 504:
print "[E]->HTTP Error 504: Gateway Time-out, Wait"
time.sleep(5)
else:
break
if htmltext.find(PageStopHtml) >= 0:
print "End Page."
break
else:
findReturn = GetHtmlFind(htmltext, ArticleListFind)
for tag in findReturn:
if tag.string != None and tag['href'].find(TargetHost) >= 0:
print "[G]->Article:" + tag.string + "|Url:" + tag['href']
articles.append({'name': tag.string, 'url': tag['href']})
page += 1
return articles;
print "[G]->GetCategory"
Mycategorys = GetCategory();
print "[G]->GetCategory->Success."
time.sleep(3)
for category in Mycategorys:
print "[G]->GetArticleList:" + category['name']
GetArticleList(category['url'])