python3爬虫学习之数据存储txt的案例详解
上一篇实战爬取知乎热门话题的实战,并且保存为本地的txt文本
先上代码,有很多细节和坑需要规避,弄了两个半小时
import requests
import re
headers = {
"user-agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
" AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari"
"/537.36M",
"cookie" : '_xsrf=H6hRg3qQ9I1O8jRZOmf4ytecfaKdf2es; _zap=296584df-ce11-4059-bc93-be10eda0fdc1; d_c0="AKBmB5e-PA-PTkZTAD1nQun0qMf_hmcEH14=|1554554531"; '
'capsion_ticket="2|1:0|10:1554554531|14:capsion_ticket|44:Yjc0NjAzNDViMTIzNDcyZDg2YTZjYTk0YWM3OGUzZDg=|2d7f136328b50cdeaa85e2605e0be2bb931d406babd396373d15d5f8a6c'
'92a61"; l_n_c=1; q_c1=ad0738b5ee294fc3bd35e1ccb9e62a11|1554554551000|1554554551000; n_c=1; __gads=ID=9a31896e052116c4:T=1554555023:S=ALNI_Mb-I0et9W'
'vgfQcvMUyll7Byc0XpWA; tgw_l7_route=116a747939468d99065d12a386ab1c5f; l_cap_id="OGEyOTkzMzE2YmU3NDVmYThlMmQ4OTBkMzNjODE4N2Y=|1554558219|a351d6740bd01ba8ee34'
'94da0bd8b697b20aa5f0"; r_cap_id="MDIzNThmZjRhNjNlNGQ1OWFjM2NmODIxNzNjZWY2ZjY=|1554558219|ff86cb2f7d3c6e4a4e2b1286bbe0c093695bfa1d"; cap_id="MGNkY2RiZTg5N2MzNDUyNTk0NmEzMTYyYzgwY'
'zdhYTE=|1554558219|18ed852d4506efb2345b1dbe14c749b2f9104d54"; __utma=51854390.789428312.1554558223.1554558223.1554558223.1; __utmb=51854390.0.10.1554558223; __utmc=51854390; '
'__utmz=51854390.1554558223.1.1.utmcsr=(direct'
')|utmccn=(direct)|utmcmd=(none); __utmv=51854390.000--|3=entry_date=20190406=1',
"authority" : "www.zhihu.com",
}
url = "https://www.zhihu.com/explore"
response = requests.get(url=url , headers=headers)
text = response.text
# print(text)
titles = []
f_titles = re.findall(r'<div class="explore-feed feed-item".*?>.*?<a class="question_link".*?>(.*?)</a>.*?</h2>',text,re.S)
for title in f_titles:
titles.append(title.strip())
# print("*"*30)
authors = []
f_authors = re.findall(r'<div class="zm-item-answer-author-info".*?>(.*?)</span>',text,re.S)[1:]
for f_author in f_authors:
# print(f_author)
author = re.sub(r'<.*?>|<a ([^>]*?)>' , "" , f_author,re.S).strip()
authors.append(author)
# print("*"*30)
content_urls = re.findall(r'<div class="zh-summary summary clearfix">.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?>.*?</a>',text,re.S)[1:]
contents = []
for content_url in content_urls:
content_full_url = "https://www.zhihu.com" + content_url
# print(content_full_url)
resp = requests.get(url=content_full_url , headers=headers)
c_text = resp.text
content = re.findall(r'<div class="RichContent-inner">*?<span .*?>(.*?)</span>',c_text,re.S)
content = str(content)
# print(type(content))
cont = re.sub(r'\\n|<.*?>',"",content).strip()
# print(cont)
contents.append(cont)
zhihu_questions = []
for value in zip(titles,authors,contents):
title,author,content = value
zhihu_question = {
"标题" : title,
"作者" : author,
"内容" : content
}
zhihu_questions.append(zhihu_question)
# for zhihu_question in zhihu_questions:
# for value in zhihu_question.values():
# print(value)
# print("=" * 50)
with open("知乎.txt" , "a" , encoding="utf-8") as fp:
for zhihu_question in zhihu_questions:
for value in zhihu_question.values():
fp.write(value)
fp.write('\n' + "="*10 + '\n')
fp.write('\n' + "*"*50 + '\n')
我们用requests库和正则来爬取
因为要一直测试爬取内容是否正确,可能运行太频繁,博主中间被封了一次号,然后修改了cookie等信息,勉强获取到了内容。
正则表达式在之前讲的很多了,也有过实战,不多赘述,我们主要来讲爬取时遇到的问题。
爬取标题时很顺利,我们只需要去除空白就行了
当爬取作者时就有了问题,我们注意到,热门话题共有10篇,也就是10个作者,但在用正则获取时,要么第一个作者不对,要么就只有9个作者,我把所有热门话题url,标题,作者和内容打印出来,打开浏览器一个一个对应标题作者和内容是否正确,发现了一个神奇的现象。
一:作者数量不对
在知乎有匿名作者,这种作者和不匿名的作者都放在同一种div下,但匿名作者在span标签内,而不匿名作者在a标签下,所以当我用正则匹配a标签的内容,无法获取匿名用户,就导致作者数量不对。于是直接获取div下的所有内容,在用sub去掉不要的内容
二:作者与标题或内容不符
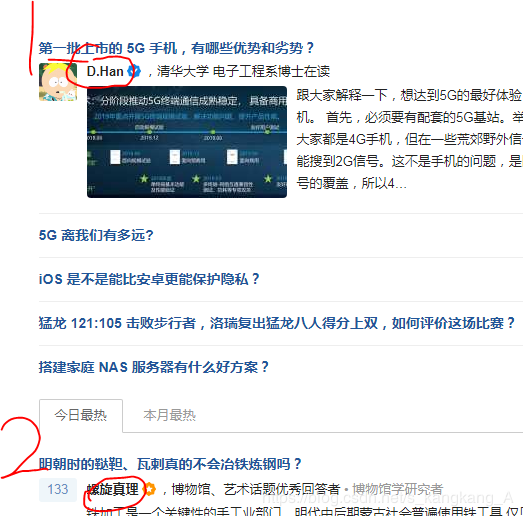
1是第一个作者,他不是我们需要的,但我们爬取的第一个就是他,2才是热门的第一个作者
未获取匿名用户
这两个是我们无法正常获取的原因
上面两个问题这样解决:
f_authors = re.findall(r'<div class="zm-item-answer-author-info".*?>(.*?)</span>',text,re.S)[1:] for f_author in f_authors: # print(f_author) author = re.sub(r'<.*?>|<a ([^>]*?)>' , "" , f_author,re.S).strip() authors.append(author)
获取所有未经处理的作者,我们不要第一个因为他不是热门话题的回答者,f_authors是含有大量标签的列表,大家可以打印看看
我们遍历这个未经处理的列表,打印未经处理的作者名,看看需要处理什么。
我们发现含有大量span标签和a标签,我们用sub函数处理
三:我们可以发现,这些内容是很长的:
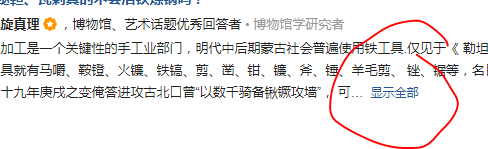
这样,我们获取的内容是不正常的,我们分析可以找到该话题对应的链接,我们加上域名就可以到这个话题的详情页
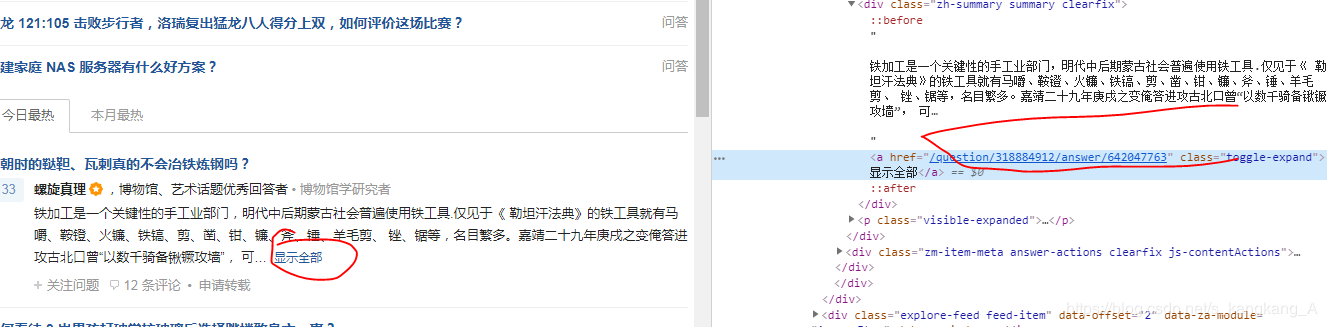
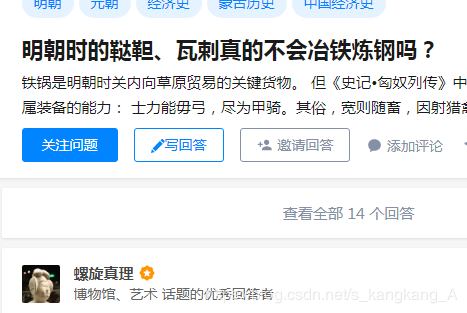
我们获取url,处理页面,获取内容,将获取的内容去掉标签等无关内容即可。
content_urls = re.findall(r'<div class="zh-summary summary clearfix">.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" .*?>.*?</a>',text,re.S)[1:] contents = [] for content_url in content_urls: content_full_url = "https://www.zhihu.com" + content_url # print(content_full_url) resp = requests.get(url=content_full_url , headers=headers) c_text = resp.text content = re.findall(r'<div class="RichContent-inner">*?<span .*?>(.*?)</span>',c_text,re.S) content = str(content) # print(type(content)) cont = re.sub(r'\\n|<.*?>',"",content).strip() # print(cont) contents.append(cont)
关于zip函数,我在上一篇爬取古诗文也用到了,很重要的函数:
zhihu_questions = []
for value in zip(titles,authors,contents):
title,author,content = value
zhihu_question = {
"标题" : title,
"作者" : author,
"内容" : content
}
zhihu_questions.append(zhihu_question)
最后就是把获取的内容保存为本地txt文档
with open("知乎.txt" , "a" , encoding="utf-8") as fp:
for zhihu_question in zhihu_questions:
for value in zhihu_question.values():
fp.write(value)
fp.write('\n' + "="*10 + '\n')
fp.write('\n' + "*"*50 + '\n')
这是最基本的保存爬取内容的方法。后续会有json,csv,数据库的相关博客续上。
运行结果:
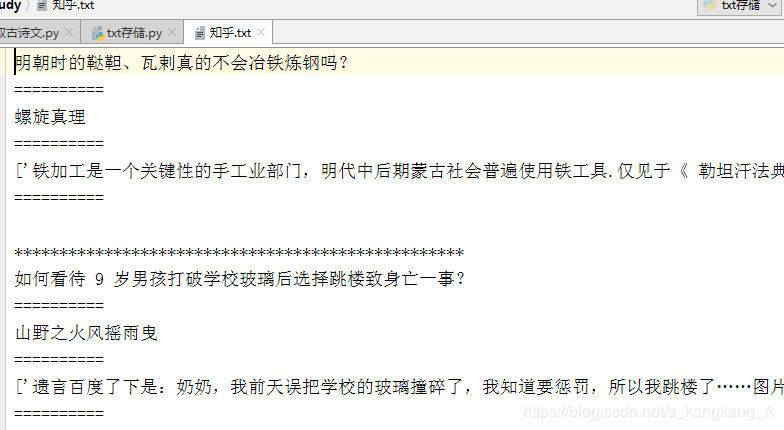
另,注释代码都是测试代码,可以参考。
补充:可能看得时候cookie信息会过期。
补充:文件打开的几种方式
1:r:只读模式,也是默认模式
2:rb:二进制只读
3:r+:读写方式
4:rb+:二进制读写方式
5:w:写方式
6:wb:二进制写方式
7:w+:读写方式
8:wb+:二进制读写方式
9:a:以追加方式,这个方式不会把原来的内容覆盖,本篇代码以此方式打开文件
10:ab:二进制追加方式
11:a+:读写方式
12:ab+:二进制读写方式
以上所述是小编给大家介绍的python3爬虫学习之数据存储txt的案详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!