Python3爬虫之自动查询天气并实现语音播报
一、写在前面
之前写过一篇用Python发送天气预报邮件的博客,但是因为要手动输入城市名称,还要打开邮箱才能知道天气情况,这也太麻烦了。于是乎,有了这一篇博客,这次我要做的就是用Python获取本机IP地址,并根据这个IP地址获取物理位置也就是我所在的城市名称,然后用之前的办法实现查询天气,再利用百度语音得到天气预报的MP3文件,最后播放,这样是不是就很方(tou)便(lan)了呢?
二、具体步骤
这次有四个py文件:get_ip.py,get_wather.py,get_mp3.py和main.py。其中get_ip.py实现了获取本机ip地址和物理位置,get_wather.py实现了根据物理位置查询天气,get_mp3.py实现了调用百度语音API把文本转化成MP3文件,main.py是我们需要运行的py文件。这里由于查询天气用的是之前的方法,所以就不需要赘述了,主要说一下get_ip.py和get_mp3.py。
(1)get_ip.py
要获取本机IP,这里有一个很简单的办法,就是打开这个网页:https://www.ip.cn/,打开之后就能看到我们的IP地址和所在地理位置信息了。因为我们可以请求一下这个网页,然后对返回的结果进行一下解析,就能得到我们想要的结果了。代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/9 16:46
"""
import re
import requests
# 获取本机IP和地理位置
def get_ip():
res = requests.get("http://www.ip.cn")
result = re.findall("<p>您现在的 IP:<code>(.*?)</code></p><p>所在地理位置:<code>(.*?)</code>", res.text)
ip, address = "", ""
if len(result):
ip = result[0][0] # IP地址
address = result[0][1].split(' ')[0] # 地理位置
else:
print("Error!")
exit()
return ip, address
(2)get_mp3.py
这里需要使用百度云,没有账号的需要先注册一下,然后搜索一下百度语音,再创建一个应用,如下:
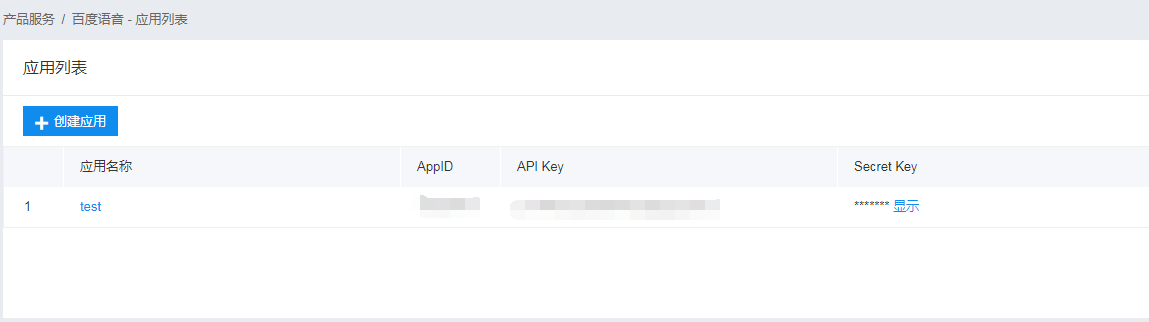
这里AppID、API Key和Secret Key在后面都需要用到,具体使用方法参见官方文档。这里还需要安装一个第三方库:baidu-aip,可以使用pip install baidu-aip进行下载安装。
下面是一个调用百度语音接口的示例:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
其中synthesis方法的各参数含义如下:

有了这个例子,做起来就简单多了,只需要将天气预报的文本传入进去就行了,然后我们可以根据自己喜好改变一下其他参数。代码如下:
"""
Version: Python3.5
Author: OniOn
Site: http://www.cnblogs.com/TM0831/
Time: 2019/2/9 17:53
"""
from aip import AipSpeech
# 你的APP_ID,API_KEY,SECRET_KEY
APP_ID = ""
API_KEY = “"
SECRET_KEY = ""
# 获取语音文件
def get_mp3(text):
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis(text, 'zh', 1, {"spd": 4, "vol": 6})
# 识别正确返回语音二进制,错误则返回dict
if not isinstance(result, dict):
with open('weather.mp3', 'wb') as f:
f.write(result)
else:
print("Error!")
exit()
三、运行结果
首先是的代码运行的结果,如下图:

然后会生成一个weather.mp3文件:

最后会播放这个MP3文件。
完整代码已上传到GitHub!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。