python微信聊天机器人改进版(定时或触发抓取天气预报、励志语录等,向好友推送)
最近想着做一个微信机器人,主要想要实现能够每天定时推送天气预报或励志语录,励志语录要每天有自动更新,定时或当有好友回复时,能够随机推送不同的内容。于是开始了分析思路。博主是采用了多线程群发,因为微信对频繁发送消息过快还会出现发送失败的问题,因此还要加入time.sleep(1),当然时间根据自身情况自己定咯。本想把接入写诗机器人,想想自己的渣电脑于是便放弃了,感兴趣的可以尝试一下。做完会有不少收获希望对你有帮助。
(1)我们要找个每天定时更新天气预报的网站,和一个更新励志语录的网站。当然如果你想更新其他内容,相信高智商的你这些都是小意思啦。博主是随便找了2个网站进行抓取。
第一步:抓取某网站天气预报信息,为我所用,因温度气候和生活指数在两个页面,于是将2个页面的数据抓取并进行整合:
这里抓取第一个页面内容,为温度,风向,日期,随便把第二天天气的也一并抓取了:
def get_content(self, html_str):
html = etree.HTML(html_str)
weather_ts = html.xpath("//div[@id='7d']/ul")
today_w = ''
tomorrow_w = ''
for weather_t in weather_ts:
today_w += weather_t.xpath("./li[1]/h1/text()")[0] + ' '
today_w += weather_t.xpath("./li[1]/p[1]/text()")[0] + ' '
today_w += weather_t.xpath("./li[1]/p[2]/i/text()")[0] + ' '
today_w += '风向' + weather_t.xpath("./li[1]/p[3]/i/text()")[0]
tomorrow_w += weather_t.xpath("./li[2]/h1/text()")[0] + ' '
tomorrow_w += weather_t.xpath("./li[2]/p[1]/text()")[0] + ' '
tomorrow_w += '风向' + weather_t.xpath("./li[2]/p[3]/i/text()")[0]
all_w = today_w + '--' + tomorrow_w
return all_w
这里抓取第二页面内容,包括穿衣指数,紫外线指数:
def get_content1(self, html_str):
html = etree.HTML(html_str)
living_ins =html.xpath("//div[@class='livezs']/ul")
today_living = ''
for living_in in living_ins:
today_living += living_in.xpath("./li[1]/span/text()")[0]
today_living += living_in.xpath("./li[1]/em/text()")[0] + ':'
today_living += living_in.xpath("./li[1]/p/text()")[0] + ' '
today_living += living_in.xpath("./li[2]/a/em/text()")[0] + ' '
today_living += living_in.xpath("./li[2]/a/p/text()")[0] + ' '
today_living += living_in.xpath("./li[3]/em/text()")[0] + ':'
today_living += living_in.xpath("./li[3]/p/text()")[0] + ' '
today_living += living_in.xpath("./li[4]/a/em/text()")[0] + ' '
today_living += living_in.xpath("./li[4]/a/p/text()")[0] + ' '
today_living += living_in.xpath("./li[6]/em/text()")[0] + ':'
today_living += living_in.xpath("./li[6]/p/text()")[0]
return today_living
第二步:抓取某网经典唯美励志语录,为了每次发送或者回复都有信息感,博主抓取了10个数据,并进行随机返回:
def Soul():
url = 'http://www.59xihuan.cn/'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)"}
res = requests.get(url, headers=headers).content
html = etree.HTML(res)
soul_sen = html.xpath("//div[@class='mLeft']")
soul_dict = {}
for soul_s in soul_sen:
soul_dict[1] = soul_s.xpath('./div[1]/div[2]/div[2]/text()')[0].strip()
soul_dict[2] = soul_s.xpath('./div[2]/div[2]/div[2]/text()')[0].strip()
soul_dict[3] = soul_s.xpath('./div[3]/div[2]/div[2]/text()')[0].strip()
soul_dict[4] = soul_s.xpath('./div[4]/div[2]/div[2]/text()')[0].strip()
soul_dict[5] = soul_s.xpath('./div[5]/div[2]/div[2]/text()')[0].strip()
soul_dict[6] = soul_s.xpath('./div[6]/div[2]/div[2]/text()')[0].strip()
soul_dict[7] = soul_s.xpath('./div[7]/div[2]/div[2]/text()')[0].strip()
soul_dict[8] = soul_s.xpath('./div[8]/div[2]/div[2]/text()')[0].strip()
soul_dict[9] = soul_s.xpath('./div[9]/div[2]/div[2]/text()')[0].strip()
soul_dict[10] = soul_s.xpath('./div[10]/div[2]/div[2]/text()')[0].strip()
i = random.randint(1,10)
return soul_dict[i]
(2)开始我们的重头戏,博主选择的是wxpy库,需要导入的库如下:
import time import json import requests import datetime import threading from queue import Queue import schedule import wxpy from weather import WeatherSpider from soul import Soul bot = wxpy.Bot(cache_path=True)
现在先设置定时器,你可以设置多个的啦,博主只设置了早上:
def main():
print("程序开始运行...")
schedule.every().day.at("10:01").do(send)
while True:
schedule.run_pending()
time.sleep(1)
接着,我们先获取抓取内容,微信好友数据,引入创建多线程:
def send():
wea_ls = '早上好,今天又是元气满满的一天\n' + WeatherSpider('101271610').run() +'您可以:'+ '\n回复"成都"获取成都天气\n回复"唯美"随机获取励志唯美语录'
send_queue = Queue()
fris = bot.friends().search('') # 这里填空会向所有好友的发送,或者填你想要单独发送的人
for fri in fris:
send_queue.put(fri)
t_list = []
for i in range(3):
t_msend = threading.Thread(target=more_thread, args=(send_queue, wea_ls))
t_list.append(t_msend)
for t in t_list:
t.setDaemon(True) #把子线程设置为守护线程,该线程不重要主线程结束,子线程结束
t.start()
for q in [send_queue]:
q.join() #让主线程等待阻塞,等待队列的任务完成之后再完成
print("主线程结束")
然后,开始向好友发送数据:
def more_thread(send_queue, wea_ls):
while True:
try:
friend = send_queue.get()
friend.send(wea_ls)
print("发送成功,a:",friend)
except Exception as ret:
time.sleep(1) # 如果你发送的好友很多,时间可以设置大一点,防止微信发送频繁,导致发送失败
continue # 这里不建议加continue,依个人微信情况而定吧
send_queue.task_done()
这里开始监听消息,并向朋友回送,一定要过滤掉群消息和公众号消息,具体为什么后面告诉你:
@bot.register()
def rcv_message(msg):
sender = str(msg.sender)
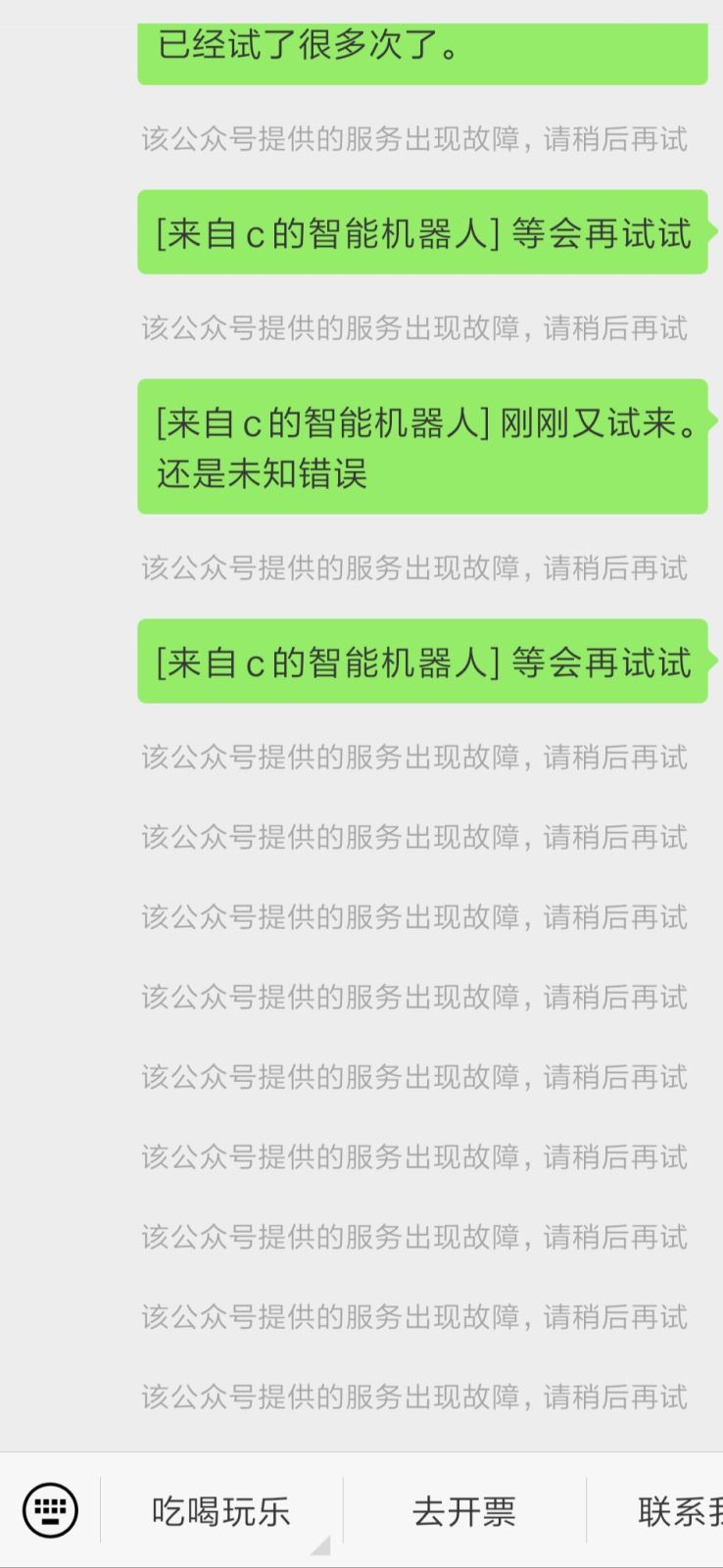
if '<MP:'in str(sender) or '<Group:' in str(sender): # 这里过滤掉群消息和公众号消息
return
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# print(now)
recv_save = ''
rev_save = '发送人:'+ sender +" 内容:"+ msg.text + ' ' + now
print(rev_save)
with open('wechat.md','a') as f: # 这里我们要把朋友发送的消息进行保存,方便查看以免遗漏重要消息
f.write(rev_save)
f.write('\n')
if msg.text == '成都':
wea_cd = '成都' + WeatherSpider('101270101').run()
return wea_cd
elif msg.text == '唯美':
return Soul()
else:
try:
return robot_tuling(msg.text)
except Exception as ret:
fri_me = bot.friends().search('virtual')[0]
fri_me.send("发送错误,信息:%s" % ret)
return ("主人不在所以我智商为0了,请尝试下回复(唯美)随机获取励志唯美语句")
下面接入图灵机器人,让实现智能聊天回复:
def robot_tuling(text):
url = "http://www.tuling123.com/openapi/api"
api_key = "a3c47b29c497e87ab0b6e566f32" # 这里我已经修改,需要自己申请一个咯
payload = {
"key": api_key,
"info": text,
}
rec = requests.post(url, data=json.dumps(payload))
result = json.loads(rec.content)
# print(result["text"])
if result["text"] == "亲爱的,当天请求次数已用完。":
return "主人不在所以我智商为0了,尝试下回复(唯美)随机获取励志唯美语句"
return result["text"]
好了,所有工作完成,看看效果,记得屏蔽了公众号,不然会有下面效果:


总结
以上所述是小编给大家介绍的python微信聊天机器人改进版(定时或触发抓取天气预报、励志语录等,向好友推送),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!