yipeiwu_com6年前
一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,...
yipeiwu_com6年前
很多网站为了避免被恶意访问,需要设置验证码登录,避免非人类的访问,Python爬虫实现验证码登录的原理则是先到登录页面将生成的验证码保存下来,然后人为输入后,包装后再POST给服务器,实...
yipeiwu_com6年前
本文实例讲述了Python实现的爬取百度贴吧图片功能。分享给大家供大家参考,具体如下: #coding:utf-8 import requests import urllib2 im...
yipeiwu_com6年前
新浪微博需要登录才能爬取,这里使用m.weibo.cn这个移动端网站即可实现简化操作,用这个访问可以直接得到的微博id。 分析新浪微博的评论获取方式得知,其采用动态加载。所以使用json...
yipeiwu_com6年前
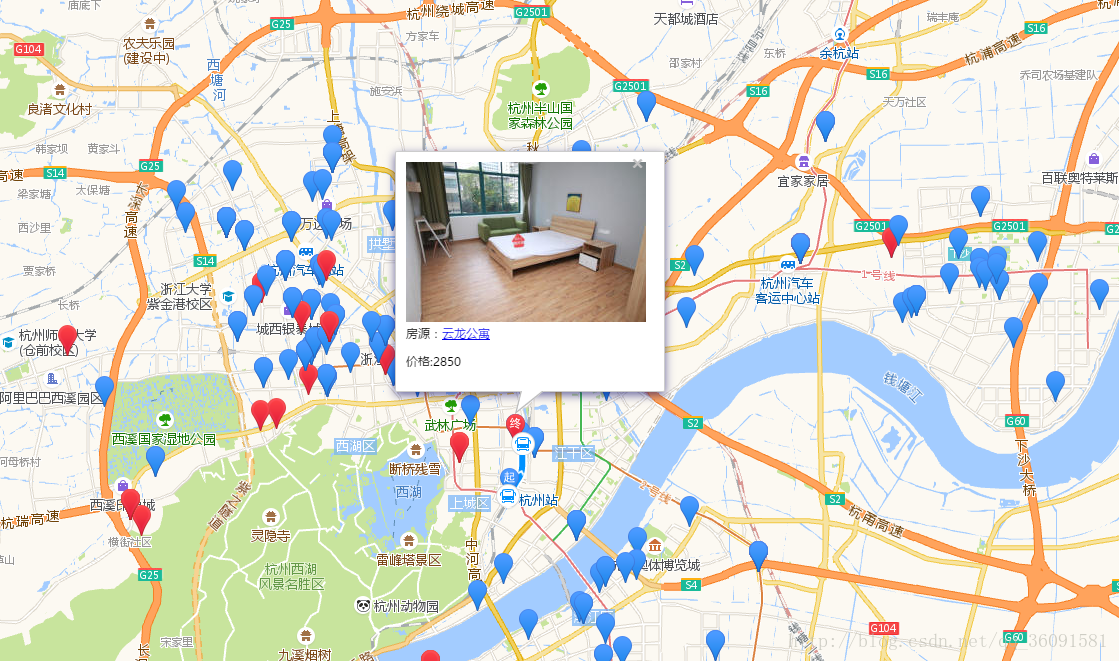
本人初学python是菜鸟级,写的不好勿喷。 python爬虫用了比较简单的urllib.parse和requests,把爬来的数据显示在地图上。接下里我们话不多说直接上代码: 1.安装...
yipeiwu_com6年前
本文实例讲述了Python实现的文轩网爬虫。分享给大家供大家参考,具体如下: encoding=utf8 import pymysql import time import sys...
yipeiwu_com6年前
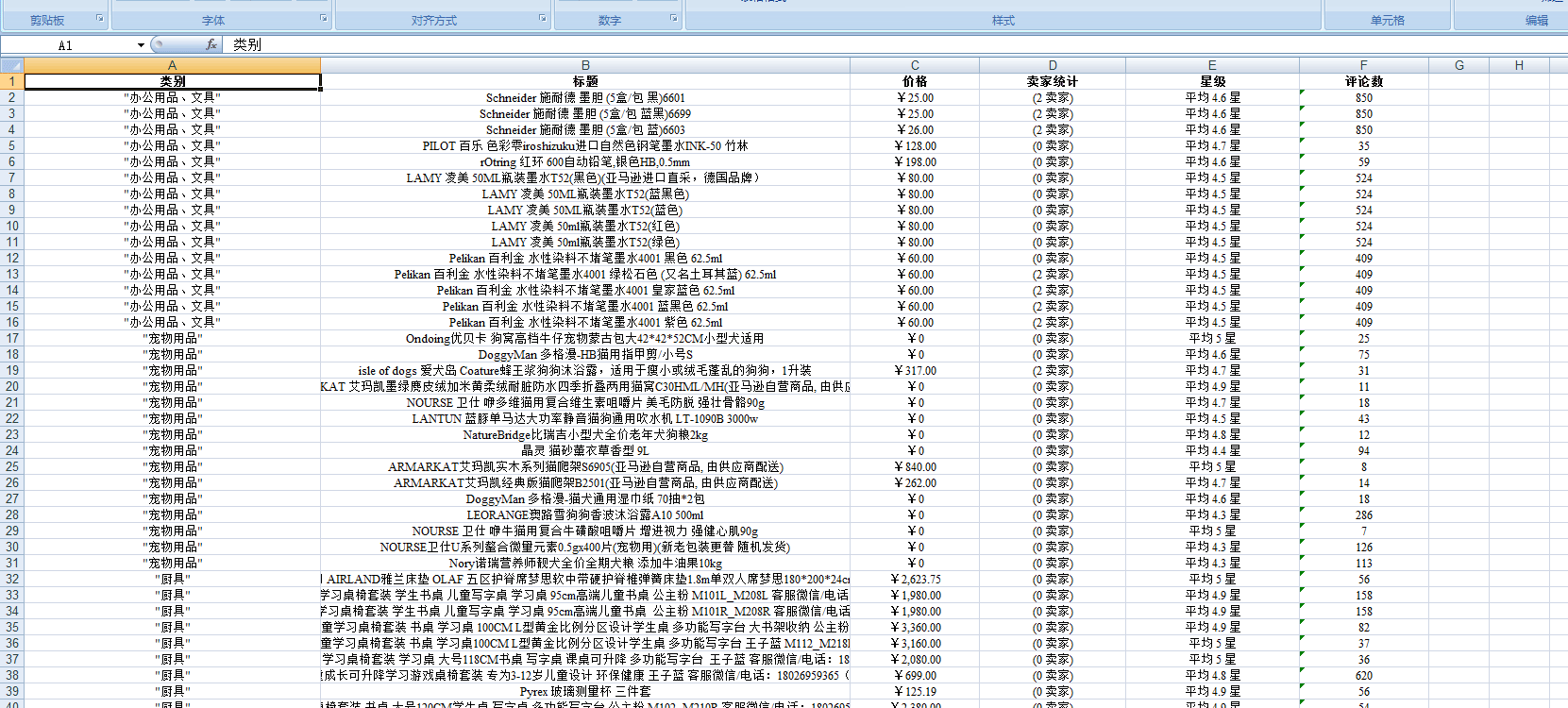
本文实例讲述了Python实现爬取亚马逊数据并打印出Excel文件操作。分享给大家供大家参考,具体如下: python大神们别喷,代码写的很粗糙,主要是完成功能,能够借鉴就看下吧,我是学...
yipeiwu_com6年前
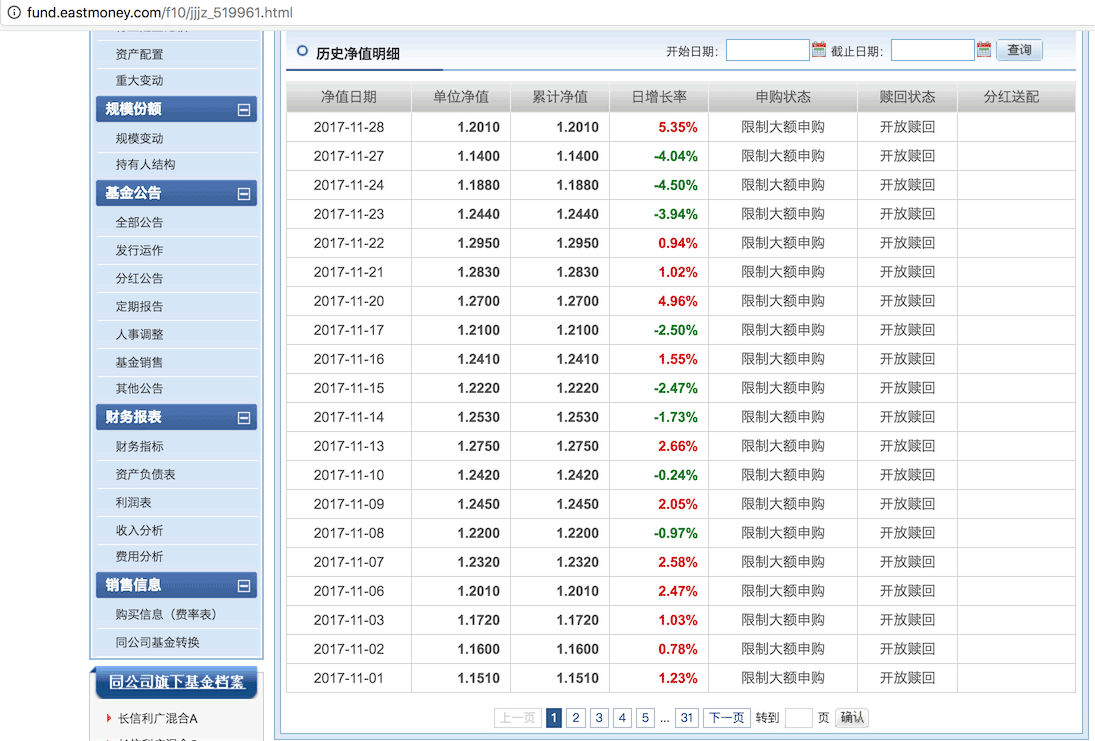
本文实例讲述了Python抓取某只基金历史净值数据。分享给大家供大家参考,具体如下: http://fund.eastmoney.com/f10/jjjz_519961.html 1、...
yipeiwu_com6年前
本文实例讲述了Python多进程方式抓取基金网站内容的方法。分享给大家供大家参考,具体如下: 在前面这篇https://www.jb51.net/article/162418.htm我们...
yipeiwu_com6年前
写在前面 本来这篇文章该几个月前写的,后来忙着忙着就给忘记了。 ps:事多有时候反倒会耽误事。 几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某...