Python实现爬取亚马逊数据并打印出Excel文件操作示例
本文实例讲述了Python实现爬取亚马逊数据并打印出Excel文件操作。分享给大家供大家参考,具体如下:
python大神们别喷,代码写的很粗糙,主要是完成功能,能够借鉴就看下吧,我是学java的,毕竟不是学python的,自己自学看了一点点python,望谅解。
#!/usr/bin/env python3
# encoding=UTF-8
import sys
import re
import urllib.request
import json
import time
import zlib
from html import unescape
import threading
import os
import xlwt
import math
import requests
#例如这里设置递归为一百万
sys.setrecursionlimit(1000000000)
##获取所有列别
def getProUrl():
urlList = []
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"}
session = requests.Session()
furl="https://www.amazon.cn/?tag=baidu250-23&hvadid={creative}&ref=pz_ic_22fvxh4dwf_e&page="
for i in range(0,1):
html=""
html = session.post(furl+str(i),headers = headers)
html.encoding = 'utf-8'
s=html.text.encode('gb2312','ignore').decode('gb2312')
url=r'</li><li id=".*?" data-asin="(.+?)" class="s-result-item celwidget">'
reg=re.compile(url,re.M)
name='"category" : "' + '(.*?)' + '"'
reg1=re.compile(name,re.S)
urlList = reg1.findall(html.text)
return urlList
##根据类别获取数据链接
def getUrlData(ci):
url="https://www.amazon.cn/s/ref=nb_sb_noss_2?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&url=search-alias%3Daps&field-keywords="+ci+"&page=1&sort=review-rank"
return url
##定时任务,等待1秒在进行
def fun_timer():
time.sleep(3)
##根据链接进行查询每个类别的网页内容
def getProData(allUrlList):
webContentHtmlList = []
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"}
for ci in allUrlList:
session = requests.Session()
fun_timer()
html = session.get(getUrlData(ci),headers = headers)
# 设置编码
html.encoding = 'utf-8'
html.text.encode('gb2312', 'ignore').decode('gb2312')
gxg = r'</li><li id=".*?" data-asin="(.+?)" class="s-result-item celwidget">'
reg = re.compile(gxg, re.M)
items = reg.findall(html.text)
print(html.text)
webContentHtmlList.append(html.text)
return webContentHtmlList
##根据网页内容过滤需要的属性和值
def getProValue():
list1 = [] * 5
list2 = [] * 5
list3 = [] * 5
list4 = [] * 5
list5 = [] * 5
list6 = [] * 5
list7 = [] * 5
list8 = [] * 5
urlList = getProUrl();
urlList.remove('全部分类')
urlList.remove('Prime会员优先购')
index = 0
for head in urlList:
if index >= 0 and index < 5:
list1.append(head)
index = index + 1
if index >= 5 and index < 10:
list2.append(head)
index = index + 1
if index >= 10 and index < 15:
list3.append(head)
index = index + 1
if index >= 15 and index < 20:
list4.append(head)
index = index + 1
if index >= 20 and index < 25:
list5.append(head)
index = index + 1
if index >= 25 and index < 30:
list6.append(head)
index = index + 1
if index >= 30 and index < 35:
list7.append(head)
index = index + 1
if index >= 35 and index < 40:
list8.append(head)
index = index + 1
webContentHtmlList1 = []
webContentHtmlList1 = getProData(list1)
webContentHtmlList2 = []
webContentHtmlList2 = getProData(list2)
webContentHtmlList3 = []
webContentHtmlList3 = getProData(list3)
webContentHtmlList4 = []
webContentHtmlList4 = getProData(list4)
webContentHtmlList5 = []
webContentHtmlList5 = getProData(list5)
webContentHtmlList6 = []
webContentHtmlList6 = getProData(list6)
webContentHtmlList7 = []
webContentHtmlList7 = getProData(list7)
webContentHtmlList8 = []
webContentHtmlList8 = getProData(list8)
##存储所有数据的集合
dataTwoAllList1 = []
print("开始检索数据,检索数据中..........")
##网页内容1
for html in webContentHtmlList1:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容2
for html in webContentHtmlList2:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容3
for html in webContentHtmlList3:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容4
for html in webContentHtmlList4:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容5
for html in webContentHtmlList5:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容6
for html in webContentHtmlList6:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容7
for html in webContentHtmlList7:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
##网页内容8
for html in webContentHtmlList8:
for i in range(15):
dataList = []
dataList.append(unescape(getProCategory(html,i)))
dataList.append(unescape(getProTitle(html,i)))
dataList.append(getProPrice(html,i))
dataList.append(getSellerCount(html,i))
dataList.append(getProStar(html,i))
dataList.append(getProCommentCount(html,i))
print(dataList)
dataTwoAllList1.append(dataList)
print("检索数据完成!!!!")
print("开始保存并打印Excel文档数据!!!!")
##保存文档
createTable(time.strftime("%Y%m%d") + '亚马逊销量数据统计.xls', dataTwoAllList1)
##抽取类别
def getProCategory(html,i):
i = 0;
name = '<span class="a-color-state a-text-bold">' + '(.*?)' + '</span>'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return ""
else:
if i<len(items):
return items[i]
else:
return ""
##抽取标题
def getProTitle(html,i):
html = getHtmlById(html,i)
name = '<a class="a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal" target="_blank" title="' + '(.*?)' + '"'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return ""
else:
return items[0]
##抽取价格<a class="a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal" target="_blank" title="
def getProPrice(html,i):
html = getHtmlById(html,i)
name = '<span class="a-size-base a-color-price s-price a-text-bold">' + '(.*?)' + '</span>'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return "¥0"
else:
return items[0]
##抽取卖家统计
def getSellerCount(html,i):
html = getHtmlById(html,i)
name = '<span class="a-color-secondary">' + '(.*?)' + '</span>'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return "(0 卖家)"
else:
return checkSellerCount(items,0)
##检查卖家统计
def checkSellerCount(items,i):
result = items[i].find('卖家') >= 0
if result:
if len(items[i])<=9:
return items[i]
else:
return '(0 卖家)'
else:
if i + 1 < len(items):
i = i + 1
result = items[i].find('卖家') >= 0
if result:
if len(items[i]) <= 9:
return items[i]
else:
return '(0 卖家)'
if i + 1 < len(items[i]):
i = i + 1
result = items[i].find('卖家') >= 0
if result:
if len(items[i]) <= 9:
return items[i]
else:
return '(0 卖家)'
else:
return '(0 卖家)'
else:
return '(0 卖家)'
else:
return '(0 卖家)'
else:
return '(0 卖家)'
return '(0 卖家)'
##抽取星级 <span class="a-icon-alt">
def getProStar(html,i):
html = getHtmlById(html,i)
name = '<span class="a-icon-alt">' + '(.*?)' + '</span>'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return "平均 0 星"
else:
return checkProStar(items,0)
##检查星级
def checkProStar(items,i):
result = items[i].find('星') >= 0
if result:
return items[i]
else:
if i + 1 < len(items):
i = i + 1
result = items[i].find('星') >= 0
if result:
return items[i]
else:
return '平均 0 星'
else:
return '平均 0 星'
return '平均 0 星'
##抽取商品评论数量 销量
##<a class="a-size-small a-link-normal a-text-normal" target="_blank" href="https://www.amazon.cn/dp/B073LBRNV2/ref=sr_1_1?ie=UTF8&qid=1521782688&sr=8-1&keywords=%E5%9B%BE%E4%B9%A6#customerReviews" rel="external nofollow" >56</a>
def getProCommentCount(html,i):
name = '<a class="a-size-small a-link-normal a-text-normal" target="_blank" href=".*?#customerReviews" rel="external nofollow" ' + '(.*?)' + '</a>'
reg=re.compile(name,re.S)
items = reg.findall(html)
if len(items)==0:
return "0"
else:
if i<len(items):
return items[i].strip(">")
else:
return "0"
##根据id取出html里面的内容
def get_id_tag(content, id_name):
id_name = id_name.strip()
patt_id_tag = """<[^>]*id=['"]?""" + id_name + """['" ][^>]*>"""
id_tag = re.findall(patt_id_tag, content, re.DOTALL|re.IGNORECASE)
if id_tag:
id_tag = id_tag[0]
else:
id_tag=""
return id_tag
##缩小范围 定位值
def getHtmlById(html,i):
start = get_id_tag(html,"result_"+str(i))
i=i+1
end = get_id_tag(html, "result_" + str(i))
name = start + '.*?'+end
reg = re.compile(name, re.S)
html = html.strip()
items = reg.findall(html)
if len(items) == 0:
return ""
else:
return items[0]
##生成word文档
def createTable(tableName,dataTwoAllList):
flag = 1
results = []
results.append("类别,标题,价格,卖家统计,星级,评论数")
columnName = results[0].split(',')
# 创建一个excel工作簿,编码utf-8,表格中支持中文
wb = xlwt.Workbook(encoding='utf-8')
# 创建一个sheet
sheet = wb.add_sheet('sheet 1')
# 获取行数
rows = math.ceil(len(dataTwoAllList))
# 获取列数
columns = len(columnName)
# 创建格式style
style = xlwt.XFStyle()
# 创建font,设置字体
font = xlwt.Font()
# 字体格式
font.name = 'Times New Roman'
# 将字体font,应用到格式style
style.font = font
# 创建alignment,居中
alignment = xlwt.Alignment()
# 居中
alignment.horz = xlwt.Alignment.HORZ_CENTER
# 应用到格式style
style.alignment = alignment
style1 = xlwt.XFStyle()
font1 = xlwt.Font()
font1.name = 'Times New Roman'
# 字体颜色(绿色)
# font1.colour_index = 3
# 字体加粗
font1.bold = True
style1.font = font1
style1.alignment = alignment
for i in range(columns):
# 设置列的宽度
sheet.col(i).width = 5000
# 插入列名
for i in range(columns):
sheet.write(0, i, columnName[i], style1)
for i in range(1,rows):
for j in range(0,columns):
sheet.write(i, j, dataTwoAllList[i-1][j], style)
wb.save(tableName)
##入口开始
input("按回车键开始导出..........")
fun_timer()
print("三秒后开始抓取数据.......,请等待!")
getProValue();
print("数据导出成功!请注意查看!")
print("数据文档《亚马逊销量数据统计.xls》已经存于C盘下面的C:\Windows\SysWOW64的该路径下面!!!!")
input()
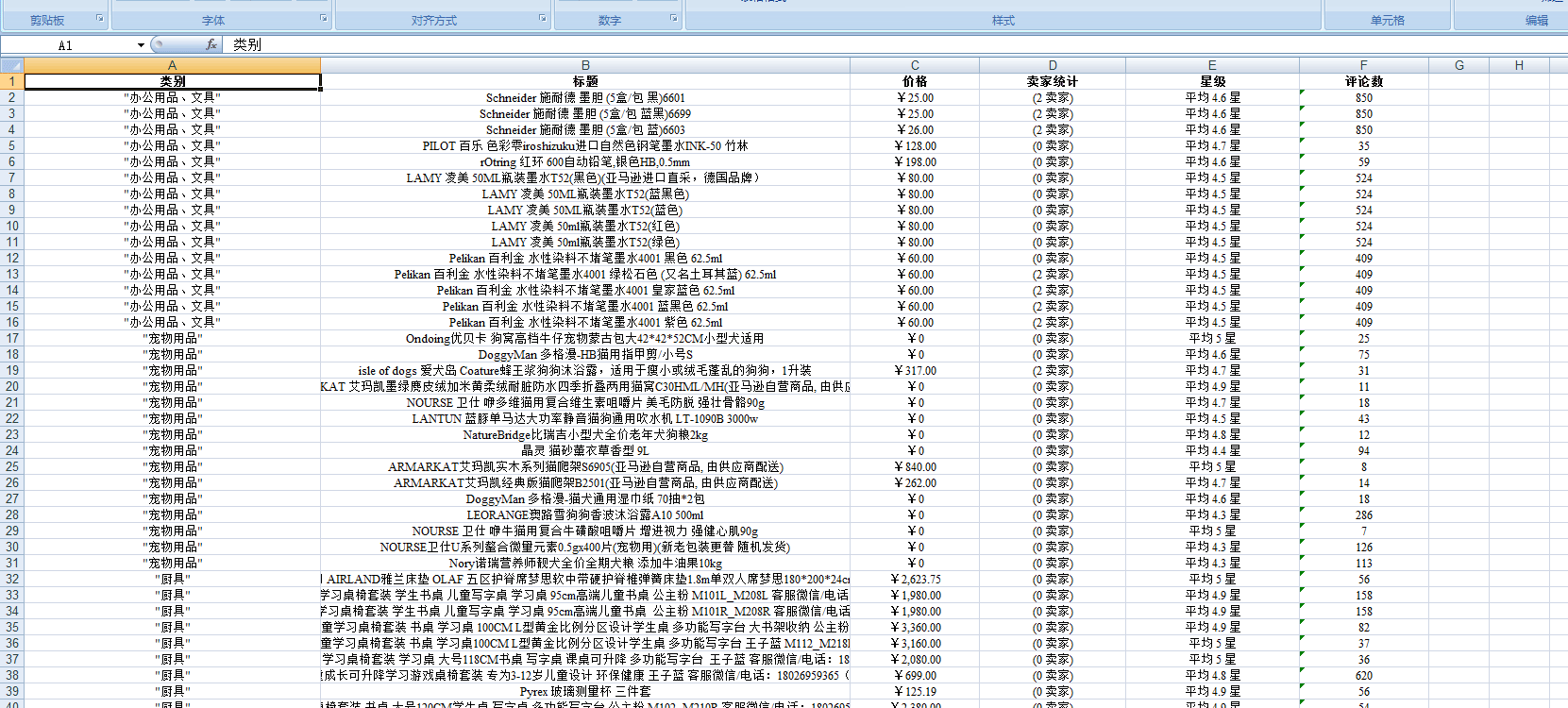
结果数据:
打包成exe文件,直接可以点击运行:打包过程我就不一一说了,都是一些命令操作:
要安装pyinstaller,打成exe的操作命令:--inco是图标,路径和项目当前路径一样
途中遇到很多问题,都一一解决了,乱码,ip限制,打包后引入模块找不到,递归最大次数,过滤的一些问题
pyinstaller -F -c --icon=my.ico crawling.py 这是打包命令
效果图:

更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。