yipeiwu_com6年前
本文实例讲述了Python实现从Web的一个URL中抓取文档的方法,分享给大家供大家参考。具体方法分析如下: 实例代码如下: import urllib doc = urllib....
yipeiwu_com6年前
以前讲过利用phantomjs做爬虫抓网页 https://www.jb51.net/article/55789.htm 是配合选择器做的 利用 beautifulSoup(文档 :ht...
yipeiwu_com6年前
有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作。Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等...
yipeiwu_com6年前
在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl urlopen返回的应答对象response(或者HTTPError实例)有两个很...
yipeiwu_com6年前
前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节。 1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Pr...
yipeiwu_com6年前
这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 复制代码 代码如下: # -*- coding: utf-8 -*- #-------...
yipeiwu_com6年前
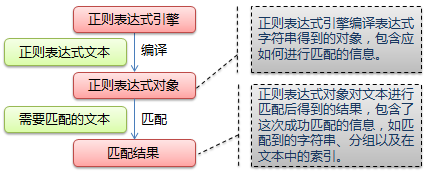
接下来准备用糗百做一个爬虫的小例子。 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少...
yipeiwu_com6年前
项目内容: 用Python写的糗事百科的网络爬虫。 使用方法: 新建一个Bug.py文件,然后将代码复制到里面后,双击运行。 程序功能: 在命令提示行中浏览糗事百科。 原理解...
yipeiwu_com6年前
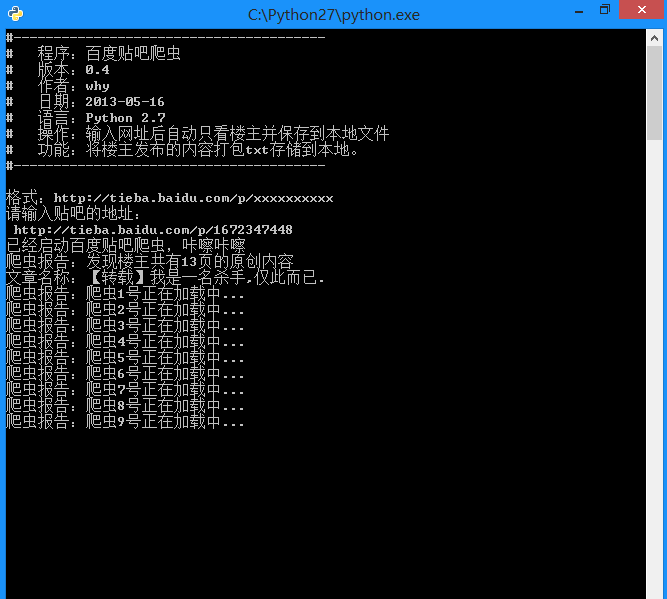
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。 项目内容: 用Python写的百度贴吧的网络爬虫。 使用方法: 新建一...
yipeiwu_com6年前
1.下载pyinstaller并解压(可以去官网下载最新版): https://github.com/pyinstaller/pyinstaller/ 2.下载pywin32并安装(注意...